其实是标题党啦... SVM 推导作为最臭名昭著的机器学习面试题,其实我在去年的这个时候准备头条实习面试的期间就已经“背诵”过了,但完全没有理解自己推导的是个什么东西。最近看台大的《机器学习技法》的课程视频,感觉这个 SVM 推导过程讲的非常清晰。最关键的是每一步的 motivation 都讲的非常清楚,正好博客也好久好久好久没有更新了,这里简单重复一下,以证明自己学会了 SVM 的推导吧~
从线性分割说起
在《机器学习基石》课程中讲了一个基于迭代的简单线性分类算法 PLA,但是对一个二分类的数据集,合法的分类线普遍是无数条。对于这无数条线我们应该选择哪条线作为我们最终分类的结果才比较好呢?
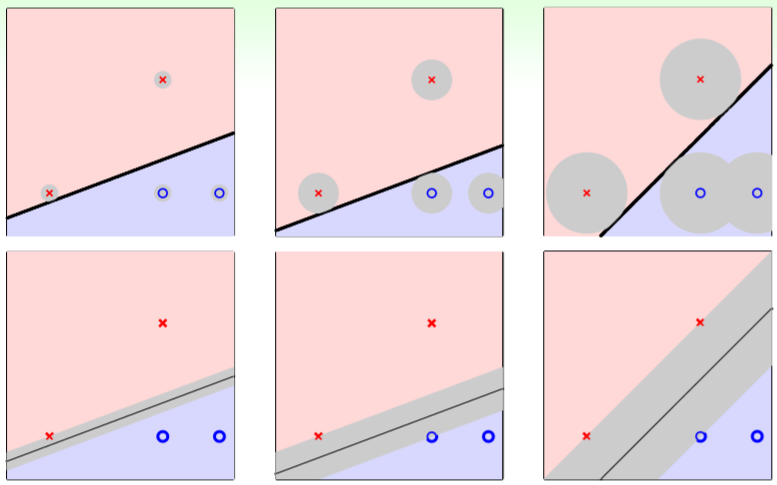
从上图来看,显然最右边这一列是比较合理的分割方法。也就说,离分类线的最近的点要尽可能的远,这样对各种噪音误差的兼容性是最好的。 用数学的定义来说就是: \[max_{w}min_{n=1...N}distance(x_n, w)\]
对于每个点来说都必须存在\(y_nw^Tx_n>0\)(如果一定要每个点都没有分割错误的话)。 在计算距离的时候,bias 显然是不应该参与进来的,所以需要把 bias 从矩阵中拆出来,变成\(h(x)=sign(w^Tx+b)\)的形式,距离就从\(distance(x,w)\)变成了\(distance(x,b,w)\)。 下面要计算点\(x\)到超平面\(w^Tx+b\)的距离,这个就是一个简单的投影,得到 \[distance(x,b,w)=\frac{|w^Tx+b|}{||w||}\]
因为上面有对于每个点来说都必须存在\(y_n(w^Tx_n+b)>0\)的条件,所以分子里面这个麻烦的绝对值式子可以直接用\(y_n(w^Tx_n+b)\)来代替(反正\(y_n\)要么是\(1\)要么是\(-1\),不会对结果有任何影响),所以得到以下式子: \[distance(x,b,w)=\frac{y_n(w^Tx_n+b)}{||w||}\]
又因为\(w^Tx_n+b\)这个东西是可以加常数放缩的,也就是说\(w^Tx_n+b\)跟\(3w^Tx_n+3b\)所代表的平面是完全一致的,所以我们完全可以通过放缩使得最小的平面求出来的值等于\(1\),这样的好处是,最小的 distance 一定是 \(\frac{1}{||w||}\)。这样做我们要求的数学式子就变为: \[max_{w}\frac{1}{||w||}min_{n=1...N}y_n(w^Tx_n+b)=1\]
但是接下来有个奇怪的问题,如果我们限制的条件是所有的\(y_n(w^Tx_n+b)\ge 1\),那一定会有一个\(w\)使得\(y_n(w^Tx_n+b)=1\)吗? 这个证明其实很简单,如果最优的\(w\)使得\(y_n(w^Tx_n+b)=1.126\),那么我们只要取\((b/1.126, w/1.126)\)这样一组解,就会比之前的\(w\)更优了。 现在优化目标已经很明显了,为了之后陈述方便,我们将最大化\(\frac{1}{||w||}\)变成最小化\(w^Tw\)。为了后续的推导方便,加了一个\(\frac{1}{2}\)的放缩。于是我们的优化函数就变成了下面这样: \[min_{w}\frac{1}{2}w^Tw\]\[min_{n=1...N}y_n(w^Tx_n+b)\ge 1\]
现在有了优化函数,如何求解呢?可以很简单的发现,这是一个非常经典的二次规划问题!给出一堆\(w\)的限制,求解一个\(w\)二次项的最优解! 对于非线性的情况,我们只要把线性的映射到非线性情况就行了,非常的 easy,真是太爽了!
为什么我们需要对偶问题
不是都爽了吗?还要搞啥呢? 真的爽吗?我们想一下,线性的情况确实蛮爽的,但是非线性的情况,当我们要将低维的特征映射的高维的时候,将\(x_n\)映射到\(z_n\),这个代价是非常巨大的。比如一个\(x_n=(x1, x2)\)特征,映射到二维就需要\(z_n=(1, x1, x2, x1^2, x2^2, x1x2)\)这么多东西,更高的维度需要的代价会更大。 为了解决这个问题,我们首先需要了解一个叫做 Lagrange Mulitipliers 的东西。这个东西在正则化的时候,我们其实已经了解过了,大致是这个形式: \[min_wE_{in}(w), w^Tw\le C \cong min_w(E_{aug}(w)=E_{in}(w)+\frac{\lambda}{N}w^Tw)\]
既然\(w^Tw\le C\)我们可以通过在后面加一个\(\frac{\lambda}{N}w^Tw\)来获得等价问题,那么\(y_n(w^Tz_n+b)\ge 1\)这个条件我们显然也可以如法炮制,大致是这个形式: \[L(b,w,a)=\frac{1}{2}w^Tw+\sum_{n=1}^N\alpha_n(1-y_n(w^Tz_n+b))\]\[\min_{b,w}(max_{\alpha_n\ge 0}L(b,w,\alpha))\]我们保证\(\alpha_n\ge 0\)这样的条件,这样就可以使得所有\(1-y_n(w^Tz_n+b)\)都符合不超过\(0\)的要求。因为如果有一个\(1-y_n(w^Tz_n+b)ge 0\),那就可以让对应的\(\alpha_n\)为无穷,优化的 max 就是无穷大了。 但是这个东西我们还是不会优化,这时候就需要引入一个叫做拉格朗日对偶问题的东西,这个东西通过一系列的证明,表示在我们这个优化形式下,这两个问题是完全等价的: \[min_{b,w}(max_{a_n\ge 0}L(b,w,\alpha))\cong max_{a_n\ge0}(min_{b,w}L(b,w,\alpha))\]
展开来写的话就是: \[max_{a_n\ge0}(min_{b,w}\frac{1}{2}w^Tw+\sum_{n=1}^N\alpha_n(1-y_n(w^Tz_n+b)))\]
下面开始魔法时刻~
如果里面的那个最小值优化是一个最值的话,那么对于每一个参数的偏导都应该是\(0\)。基于这一点,我们就可以做一些有趣的事情了。 首先对里面的\(L(b,w,\alpha)\)求\(b\)的偏导,可以得到如下式子: \[\frac{\partial L(b,w,\alpha)}{\partial b}=-\sum_{n=1}^N\alpha_ny_n=0\]
这个结论其实就有点神奇了,但是更神奇的地方在于,我们把\(L(b,w,\alpha)\)展开,发现\(b\)的系数恰好就是这个\(-\sum_{n=1}^N\alpha_ny_n\)!也就说\(b\)这一项直接就可以消掉!
继续我们的魔法之旅,下面对\(L(b,w,\alpha)\)求\(w_i\)的偏导: \[\frac{\partial L(b,w,\alpha)}{\partial w_i}=w_i-\sum_{n=1}^N\alpha_ny_nz_{n,i}=0\]
这样就得到了一个有趣的结论,\(w=\sum_{n=1}^N\alpha_ny_nz_n\)。 将这个结论带入回原来的式子,可以得到: \[max(\frac{1}{2}||\sum_{n=1}^N\alpha_ny_nz_n||+\sum_{n=1}^N\alpha_n)\\ a_n\ge0, \sum_{n=1}^N\alpha_ny_n=0, w=\sum_{n=1}^N\alpha_ny_nz_n\]
所谓的 KKT 条件,其实也就是上面式子的几个条件了,还有一个原来定义中的条件\(y_n(w^Tx_n+b)\ge1\),当然还有一个最有趣的 KKT 条件就是\(\alpha_n(1-y_n(w^Tz_n+b))=0\),因为在优化的过程中,我们要求最后结果的最大值,而两个非负数相乘最后想要结果最大的话,必须其中一个为\(0\),那么上面这个条件就必须成立。 通过取负数将优化最大值变成优化最小值,然后展开可以得到: \[min_{\alpha}\frac{1}{2}\sum_{n=1}^N\sum_{m=1}^N\alpha_n\alpha_my_ny_mz_n^Tz_m-\sum_{n=1}^N\alpha_n\\ a_n\ge0, \sum_{n=1}^N\alpha_ny_n=0\]
诶,这个东西的形式是不是有点眼熟?没错,就是二次规划,太爽了,对偶问题我们现在也会求解了! 求解出\(\alpha\)之后,就可以通过\(w=\sum_{n=1}^N\alpha_ny_nz_n\)求出\(w\)。那我们的 bias 呢?还记得\(\alpha_n(1-y_n(w^Tz_n+b))=0\)这个 KKT 条件吗?在\(\alpha_n>0\)的时候,我们就可以求出对应的 bias 了,而那些\(\alpha_n>0\)所对应的\(n\),其实就是所谓的支持向量! 当然了,这个时候聪明的读者就会发现,你这个不还是有一个\(z_n^Tz_m\)吗?复杂度并没有降低啊?
久等了,核方法!
核方法其实跟 SVM 的推导并没有什么直接关系,但是在 SVM 的使用中却是大放异彩的。 所谓的核方法,其实就是一些神奇的\(z_n^Tz_m\)求法,这些核方法可以完成很好的空间变换功能,甚至将原来的特征空间变换到无限维,正是核方法的出现,才使得 SVM 在某一个历史时期“一统江湖”的。 比如我们有一个垃圾特征空间变换,将\(x_n=(x_1, x_2, x_3, ..., x_d)\)变换到\(\phi_n=(1, x_1, x_2, ..., x_d, x_1x_2, ..., x_1x_d, x_2x_1, x_2^2, ..., x_2x_d, ..., x_d^2)\)。 现在我们想知道\(\phi_n(x)^T\phi_n(x^*)\),直接乘起来的话复杂度是\(O(d^2)\)。我们通过观察式子,进行一定程度的优化可以发现\(\phi_n(x)^T\phi_n(x)=1+x^Tx^*+(x^Tx^*)(x^Tx^*)\)。这样复杂度就是\(O(d)\)了,是不是很棒? 当然了,还有很多例如 RBF 之类的比较复杂的核方法,这里就不加赘述了,在实际应用中通常将\(z_n^Tz_m\)换成\(K(x_n, x_m)\)就代表核方法啦。
虚假的 SVM 和真正的 SVM
其实上面讲的 SVM 跟实际使用的 SVM 并不完全一致,主要问题出现在大前提上,就是\(y_n(w^Tx_n+b)\ge1\)这个定义。这个定义要求我们每个点都不能分割错误,过于严格,因为有一些噪音的结果是不需要考虑的。我们的 SVM 需要容忍一些分割错误。 我们将原来的 SVM 扩展一下,形式如下: \[min_{b,w,\xi}\frac{1}{2}w^Tw+C\sum_{n=1}^N\xi_n\\ y_n(w^Tz_n+b)\ge1-\xi_n, \xi_n\ge0\]
其中参数\(C\)就是用来 trade-off 容错率和分割线的鲁棒性的,参数\(\xi_n\)就是表示这个点到底犯了多少错。 用 Lagrange Mulitipliers 重写这个优化式子,形式是这样: \[L(b,w,\xi,\alpha,\beta)=\frac{1}{2}w^Tw+C\sum_{n=1}^N\xi_n+\sum_{n=1}^N\alpha_n(1-\xi_n-y_n(w^Tz_n+b))+\sum_{n=1}^N\beta_n(-\xi_n)\]
\[max_{\alpha_n\ge0, \beta_n\ge0}(min_{b,w,\xi}L(b,w,\xi,\alpha,\beta))\]
跟原来一样,通过求\(\xi_n\)的偏导可以发现: \[\frac{\partial L(b,w,\xi,\alpha,\beta)}{\partial \xi_n}=C-\alpha_n-\beta_n=0\] 跟之前的 bias 一样,我们将式子展开之后,发现\(\xi_n\)的系数就是上面这个等于\(0\)的式子,所以\(\xi_n\)这一项就没了。但是需要多一个\(0\le\alpha_n\le C\)的条件。很神奇,这一项没了之后,我们的式子又开始变得眼熟起来: \[max_{0\le\alpha_n\le C}(min_{b,w}\frac{1}{2}w^Tw+\sum_{n=1}^N\alpha_n(1-y_n(w^Tz_n+b)))\]
后面的事情就很显而易见了,前面都推导过了,这里也就不加赘述了。