各种课程资料请参考上一篇文章
Lecture 7: Automatic Code Generation - TVM Stack
现在深度学习的框架非常多,而这些乱七八糟框架写出来的代码通常又跑在乱七八糟的设备上。这其中最为关键的问题就是:如何让深度学习代码在不同的设备上都跑出最好的效果。 众所周知,如果软件架构出现了什么难以解决的问题,那就加个中间层,看看能不能解决。如果还不能解决,那就再加个中间层( 目前各家(比如 TensorFlow XLA、NVIDIA TensorRT 等)采用的设计思路就是将各个框架写出来的网络转换成一种统一的表示形式,也就是所谓的 Graph IR。
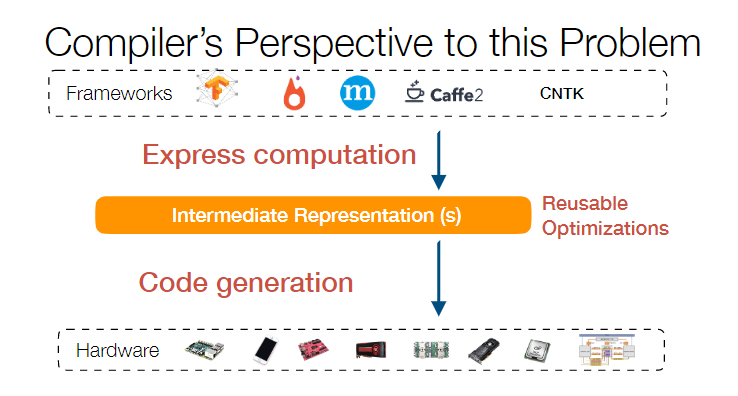
当然了,最后 IR 如果想要运行,那你还是要把 IR 变成机器码才可以。对于不同的硬件平台、数据格式、精度、线程结构都要写一堆不同的代码生成规则和优化规则。 这个问题是 TVM 的技术背景了。前面说了,如果还解决不了问题,那就再加个中间层。TVM 加的中间层就是所谓的 Tensor Expression Language 表示方法。这个 idea 来自于 Halide,核心在于把代码的计算和调度分开。

举个具体的例子,最简单的一个向量相加,用 TVM 实现起来长这样:
1 | C = tvm.compute((n,), lambda i: A[i] + B[i]) |
得到的 C 代码是:
1 | for (int i = 0; i < n; ++i) |
加上一些额外的循环控制(就是上篇文章中讲的 cache 优化)
1 | C = tvm.compute((n,), lambda i: A[i] + B[i]) |
生成的代码就变成了:
1 | for (int xo = 0; xo < ceil(n / 32); ++xo) |
甚至可以绑定特定的变量:
1 | C = tvm.compute((n,), lambda i: A[i] + B[i]) |
这样就出来一个 CUDA kernel 代码:
1 | int i = threadIdx.x * 32 + blockIdx.x; |
TVM 的核心就是一些调度原语,比如下图这些:
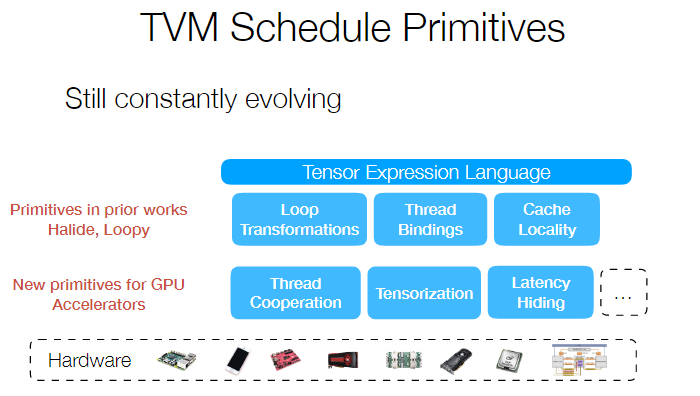
还有 TVM 最有趣的部分 AutoTVM,可以用 learning 的方式对代码进行自动优化,不过这个东西在课程中并不是重点,所以只是简单的提及了一下。
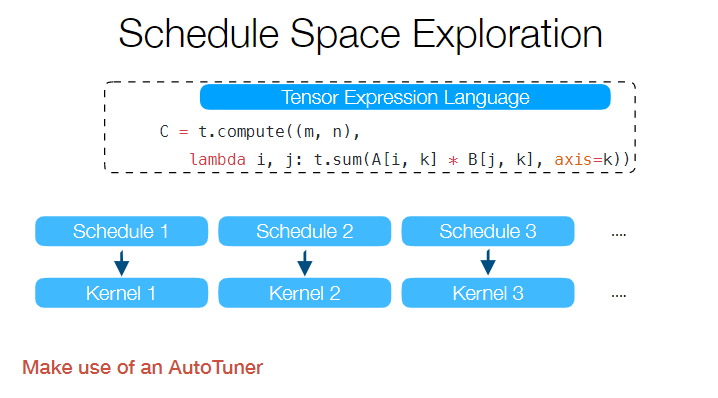
在我理解,TVM 就是一个 Graph IR 的优化框架,或者说是底层算子的高阶表示。
Lecture 8: Hardware Specialization in Deep Learning
这一讲主要介绍 TVM 技术栈中的重要部分 VTA。对于硬件我不是特别熟悉,也不是特别感兴趣,所以这章就随便看看了。 VTA: 开源AI芯片栈 Tianqi 的这篇文章概括性的讲述了 VTA 的意义。 总体来说,就是根据 RISC 的思想,设计了一套硬件架构。TVM 充当编译器,VTA 充当底层计算硬件,两者配合达到良好的效果。

Lecture 9: Memory Optimization
这一讲我觉得还蛮有意思的,讲的是深度学习的内存优化。 主要内容来自于这篇论文:Training Deep Nets with Sublinear Memory Cost 这一讲的核心问题在于,为什么我们要用 autograd 来形成计算图,而不是直接使用 BP?
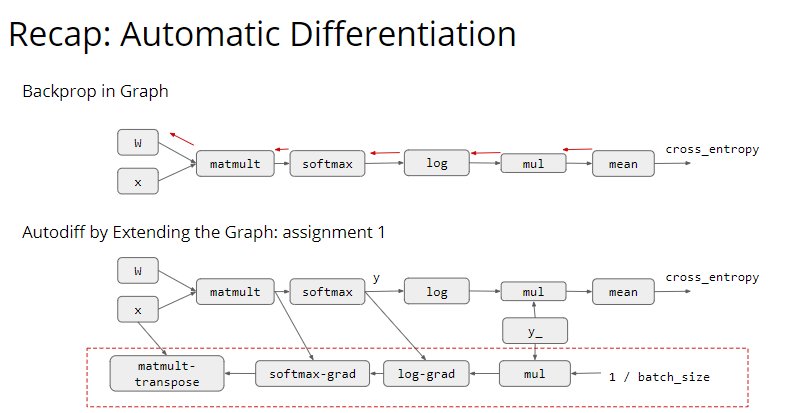
这个问题的答案其实就本节课的标题:Memory Optimization。我们要优化内存的使用,所以要用计算图。 假如只有前向传播的话,我们其实可以通过计算图的层次结构来复用内存:
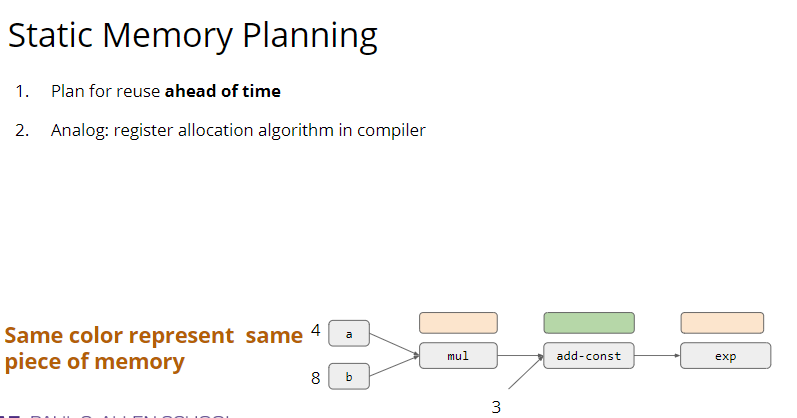
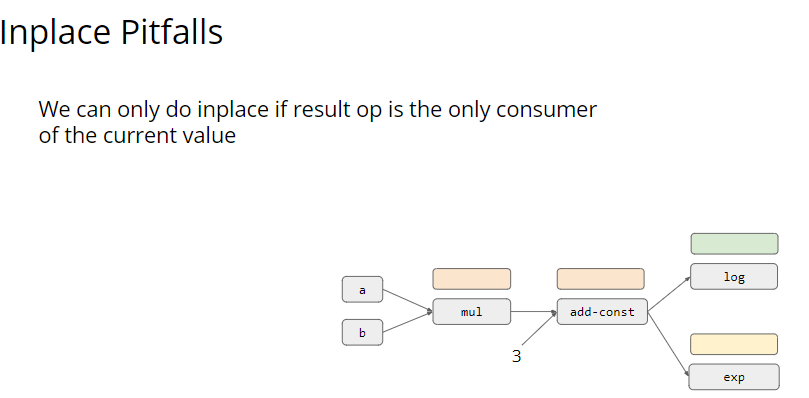
这个内存复用有两个原则:Inplace 和 Normal Sharing。 所谓 Inplace 就是输出的内容直接存到输入内存的地方。Normal Sharing 则是重复使用那些不被需要的内存。 显然 Inplace 也有一些失效的时候,当输入的内容还被其他输出依赖时,我们之前的输出就不能使用这块内存。
回到我们最开始的问题,为什么我们要用 autograd 的计算图来代替 BP?
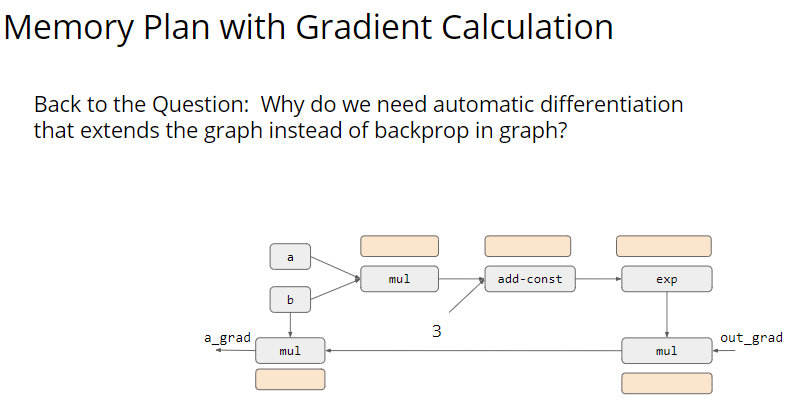
这个问题其实没有在 slides 中说清楚。看了看其他人的理解,都是觉得 BP 要存中间结果,所以比较费内存。但是计算图也要存中间结果啊?所以有点费解。我的理解是,计算图可以更好的捕获变量之间的依赖性,就像上面这个图一样。如果用 BP,每一步中间结果都要存起来,但是如果用 autograd,就可以全程 Inplace。 后面讲了一些利用两个原则优化内存的例子,都不是很难理解。但是问题在于,不管我们怎么复用,整体的空间复杂度仍然是线性增长的。
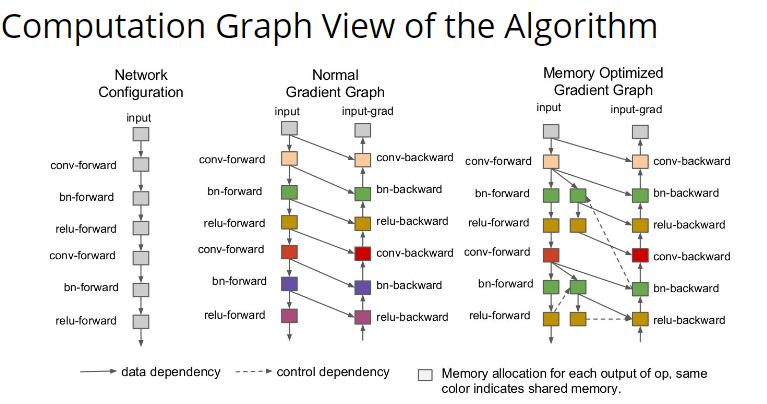
这时候有个牛逼做法就是保存 \(\sqrt{N}\) 个中间节点,每次需要反向传播的时候,就从这个中间节点往下算 \(\sqrt{N}\) 步。这样内存就是 \(O(\sqrt{N})\) 级别了,是不是跟 ICPC 竞赛里面常见的分块算法一模一样? 感觉内存优化这部分还是有些东西不太清楚,需要回头看一下论文。看完论文补充一下这部分的内容。 接下来是 assignment 2。 这次作业感觉工作量还是很大的,首先是要满足作业的第一个要求,把 test_tvm_op.py 里面的所有测试都跑通:
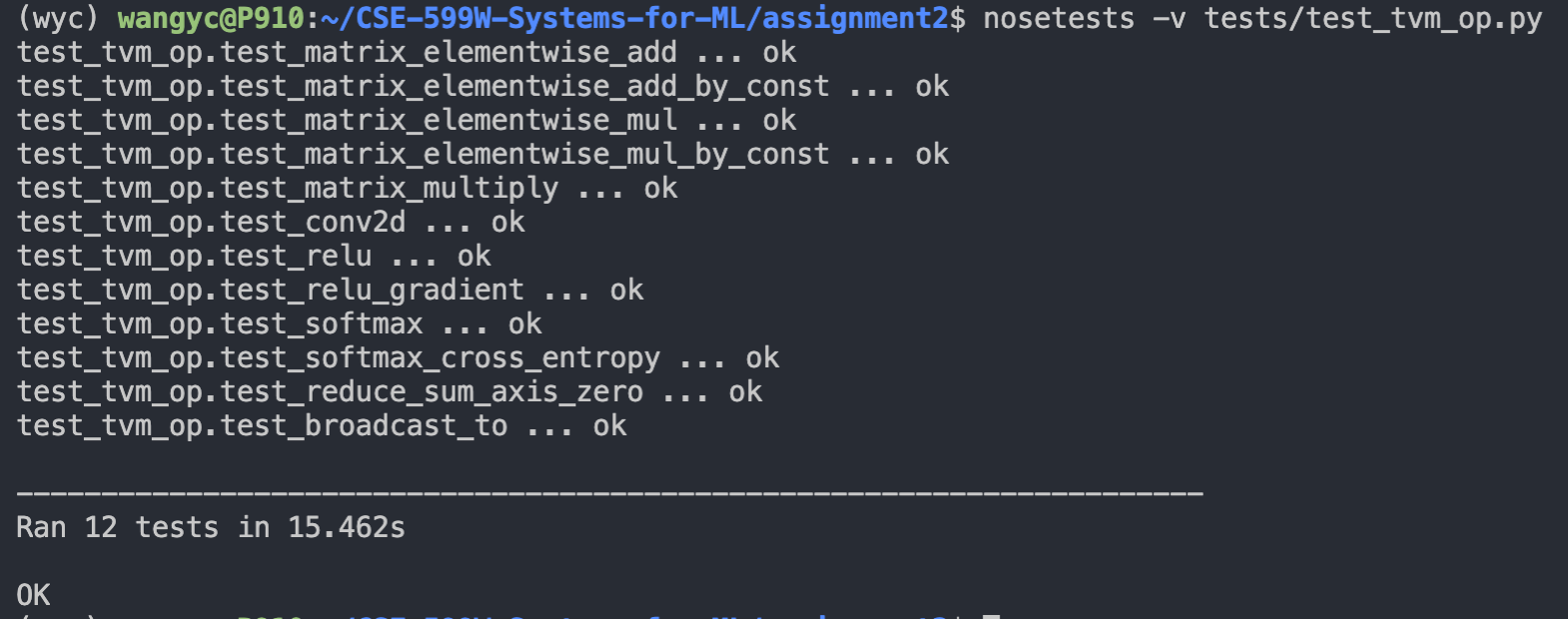
这一步主要要参考 TVM Documentation 的写法,把这些算子都补齐。其中一些算子的作用还是比较迷惑的,要看测试才知道是什么意思。TVM 的写法有些地方也比较古怪,要自己慢慢尝试。 然后是满足第二个要求,跑通 mnist 的两个方法:
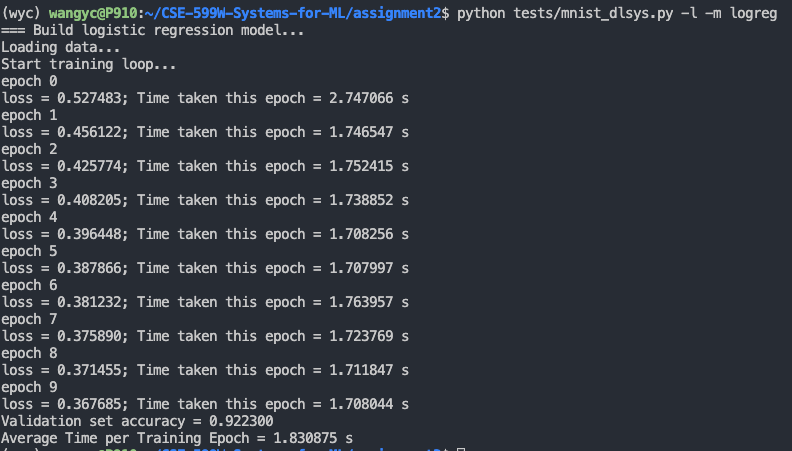
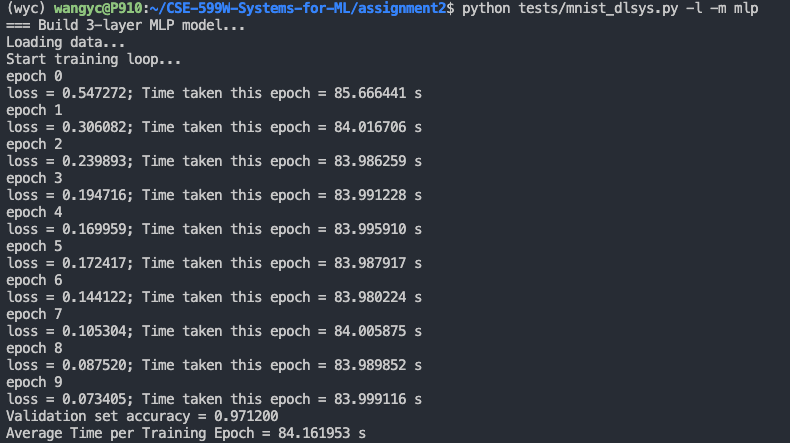
这一步是要把 autodiff 的内容补全,其实很简单,但是有些地方可能不太清楚他到底想让你写什么东西,仔细看看调用代码,然后把函数补全就好了。 从上面的截图可以看出,我们自己写的算子效果非常垃圾,跑一遍 mlp 要 80s,下面就是如何优化矩阵乘法算子了:
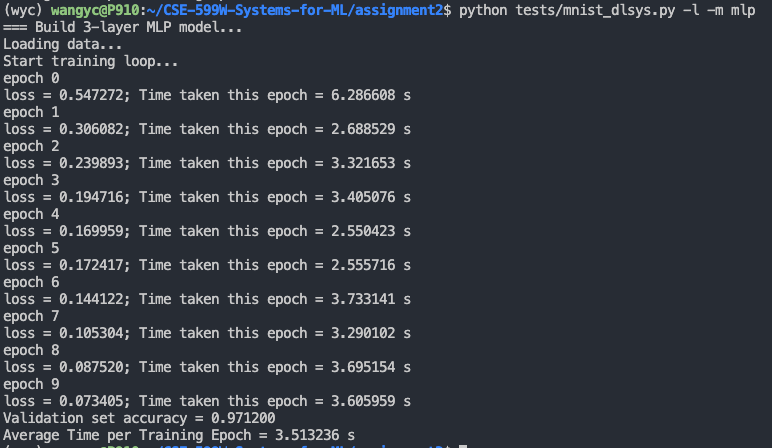
主要思路还是来自于 Lecture 6,只要简单的把矩阵分一下块,调整一下循环顺序,然后再并行一下,就可以得到 20x 的优化效果。
1 | s = tvm.create_schedule(C.op) |
更多精细的优化在 如何利用TVM快速实现超越Numpy的GEMM 这篇文章中可以找到,非常牛逼。
Lecture 10: Parallel Scheduling
在内存分配之后,第10讲讲的是并行调度的问题。 首先讲了一下 Model Parallel 和 Data Parallel 的模式,比较基础。
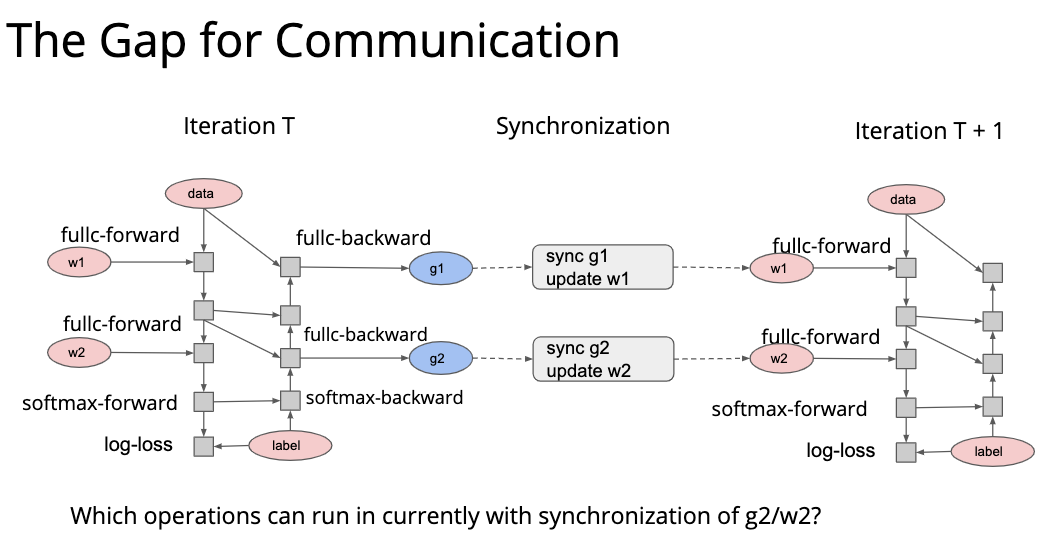
因为现实的运算中存在着各种复杂的同步关系,所以我们需要一个自动调度器。 这个自动调度器需要调度各种各样的资源,包括数据、随机数生成器、网络通信等等;也要调度各种各样的操作。 对于深度学习来说,基于计算图的调度就非常自然。因为计算图是一个 DAG,各种依赖复用关系都非常明显。但是基于计算图的这种调度对于一些什么写后读、读后写的问题可能不是特别敏感,所以还增加需要 mutation aware 这种调度方式。
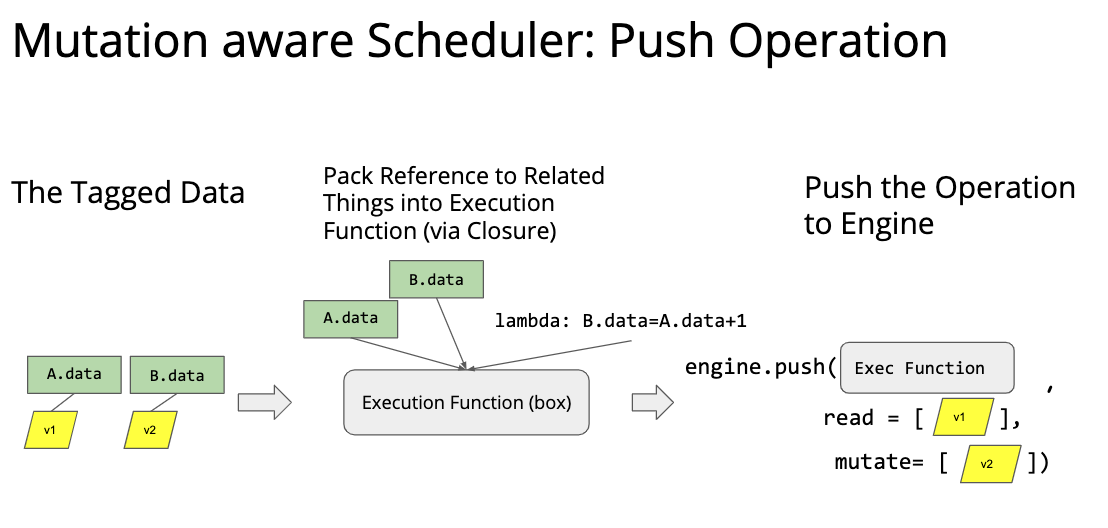
后面给了一个很简单的队列调度的例子,看看就能懂。
Lecture 11: Distributed Training and Communication Protocols
这一讲讲的主要是参数的 Synchronization 问题。 首先介绍了一种叫做 Allreduce 的操作,感觉就是在中间把分布式程序拦了一下:

然后讲了几种网络拓扑对 Allreduce 操作的影响,看起来比较简单。 之后介绍了 Parameter Server,这个在实习的时候接触的蛮多,其实就是个 KV,用 PS 去更新和获取参数,他们内部甚至搞了个无锁 hash 表...
Lecture 12: Model Serving
终于到了最后一讲,这一讲主要讲的是模型部署在现实应用中的问题。

主要分为模型压缩和服务系统两个部分来进行讲解。 模型压缩的第一个部分是矩阵/向量分解,这个矩阵分解套路很简单很常见,向量分解没见过,也没太看懂,有空可以仔细研究一下。大概是把一个 cnn 分解成几个 cnn,但是能达到相似的效果。 然后网络剪枝,其中一个思路是 prune the connections。想法很简单,每次增加前向传播的 theshold,减少连通性。 第二个思路是 weight sharing,首先对参数进行聚类,相似的参数就看做一个参数,再对他们进行统一的更新。 模型的低比特量化也是一个很有趣的思路,通过降低模型数据存储的精度,来压缩模型并且尽量保持精度。 还有知识蒸馏,用一个大模型去训练一个小模型。上周末实验室讲座有个大哥讲的就是这个内容,但是我因为家里有急事所以没听到,不过获得了 PPT,之后自己补一补吧。 第二个部分就是服务系统了,服务系统的目标是编写程序的灵活性、GPU 上面的高效率以及延迟满足 SLA(service-level agreement)。 然后讲了一个叫 Nexus 的系统,看起来有些难以理解,先略过吧~