周末要在实验室搞个类似讲座之类的东西,先在这里写一下讲座内容,理清思路。也是对最近一个月的学习内容做一个总结。
从 TVM 开始
TVM: an automated end-to-end optimizing compiler for deep learning. OSDI`18 AutoTVM 其实是 TVM 的一个组件,那么先要搞清楚 TVM 是个啥。
Apache TVM (incubating) is a compiler stack for deep learning systems. It is designed to close the gap between the productivity-focused deep learning frameworks, and the performance- and efficiency-focused hardware backends. TVM works with deep learning frameworks to provide end to end compilation to different backends.
简单来说,这是一个深度学习编译器。输入是 high-level DL program (Pytorch TensorFlow etc.) 输出是 low-level optimized code。
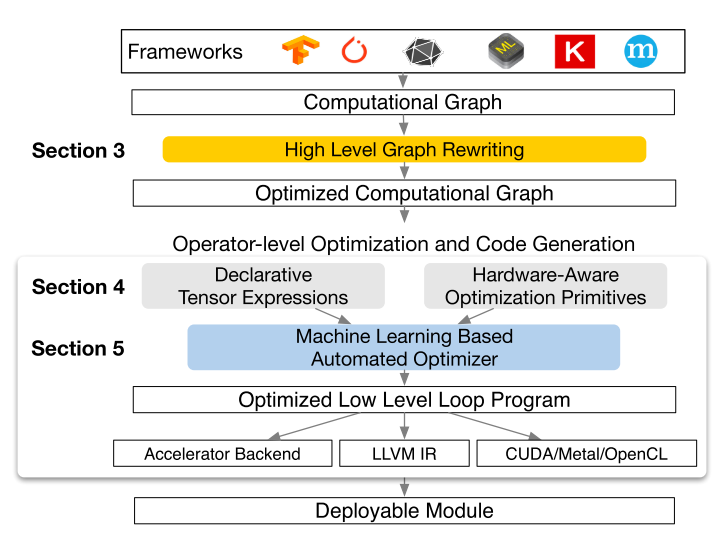
本文章的主题其实就是图里面蓝色的那个 Machine Learning-Based Automated Optimizer。 不过在进入主题之前先谈一谈这个 TVM 的意义吧,通过 TVM 的意义其实我们就可以自然的了解到为什么我们需要 AutoTVM。这些内容其实在之前的两篇文章里面都有谈过。 在之前很多厂商都搞过深度学习编译器,比如 TensorFlow XLA、NVIDIA TensorRT 等等。之前的搞法通常都是先把这些乱七八糟深度学习框架前端统一成一个 Graph IR,再对这个 Graph IR 进行一些例如 Operator Fusion 和 Constant Folding 之类的优化,然后将 Graph IR 映射到 XLA 算子或者 cuDNN 中,这些算子很多是由专业的工程师进行手工优化,效果拔群,通过这个过程实现神经网络的高效。 问题在于,你的模型需要在一大坨设备上面跑(比如手机、树莓派、GPU、CPU...)这些设备的运算能力和优化方式都有所不同,那么就需要每个设备都搞一个编译框架,然后由很多很多工程师去实现很多高效的算子用来映射。一个更夸张的发展趋势是,很多 AI 芯片厂商会把一些常用算子(如卷积层)直接设计一个硬件模块去加速,这样会导致只要出一个牛逼网络,那 AI 芯片就会多做一个模块去对网络的某些公共运算进行加速,然后工程师也会设计相关的算子,不停加班,永不失业。 还有个问题就是,比如 Operator Fusion 这种优化,有一些算子(如卷积+池化+relu)的融合模块已经在 cuDNN 中写好了,那么 Operator Fusion 的时候就可以直接对应过去。但是随着 DL 的发展,越来越多算子都可能进行融合,但是因为底层的实现还没做好,导致在图级别的优化会出现捉襟见肘的情况。很多时候优化会倾向于使用成熟的算子,避免那些还没有优化很好的融合方式。 以及一个在 learning 领域广泛出现的问题——长尾分布。对于那些通用的优化来说,优化一下可以产生很大的性能提升,但是对于那些长尾的优化来说,优化一次的代价过高,产生的利益也没有那么丰厚。 显然,解决问题的核心就在于如何对不同的硬件和不同的算子进行一波通用的优化。
AutoTVM 初探
对于上面这个问题,TVM 给我们的答案是 AutoTVM,一个 Automating Optimization。 在谈论这个问题之前,我们还要再复习一下体系结构的内容。其实这个在前两篇文章中也讲过很多。
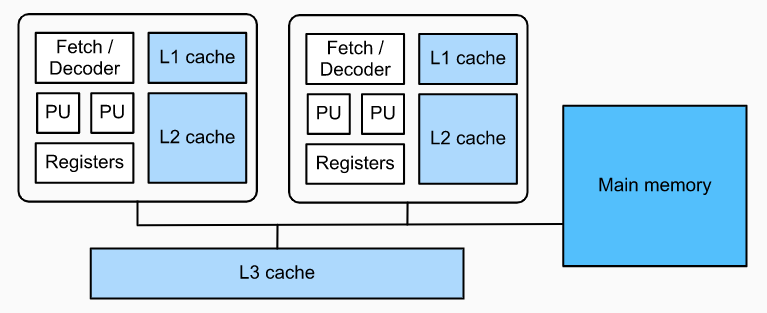
一个简单的 CPU 架构可以概括为上面这样,这个 CPU 有两个核心,每个核心都有自己 L12 cache,然后也支持 SIMD,也就是 fetch 一个指令可以在两个 PU 上面运算。当然现在很多处理器都支持超线程,也就是说一个核心有两个硬件线程,每个核心在操作系统中其实是两个核心。然后现在最厉害的 SIMD 指令叫做 AVX-512,可以在每个 cycle 同时对 16 个 float32 进行运算。 所以对于 CPU 而言,最为常用的优化其实就是三种:Parallelization(多核并行)、Vectorization(SIMD)、Cache。还有一些诸如是否进行循环展开之类的优化。 下面用 TVM 实现一个最简单的矩阵乘法,程序来自于 AutoTVM 教程
1 | def matmul_v0(N, L, M, dtype): |
上面的程序只包括了 Cache 优化,方式就是常见的矩阵乘法循环变量 reorder 和矩阵分块。注意,这里矩阵分块的 magic number 是 8, 也就是说把这个矩阵分成 8*8 的小块,使得 cache 的 hit rate 更高。 但是对于这样的 magic number,没有经验的人是很难找到最优的数值的。而且这个数值跟很多硬件因素都有关系,很多时候我们不能对硬件的所有因素都产生全面的了解,这个时候就需要 AutoTVM 的帮助了。 用起来也很简单,其实就是指名一下哪些参数需要搜索。比如下面的程序就是指明要搜索 tile size:
1 |
|
这其实也是系统设计的艺术,首先 TVM 把运算与 schedule 进行解耦,然后一部分 schedule 由用户进行实现,一部分需要精细调整的内容由一个 ML 算法进行搜索,从而达到一个易用性和性能的 trade-off。相对应的是 Facebook 做的 Tensor Comprehension,要解决的问题跟 TVM 是类似的,但是选择的是利用 polyhedra model 进行一个类似端到端的优化过程,但是优化的空间其实比 TVM 这种 schedule space 模型要差一些,所以效果也会打些折扣。一些相关的讨论可以在如何看待Tensor Comprehensions?与TVM有何异同?上面看到。 对于 GPU 来说,由于架构跟 CPU 存在区别,所以优化的方式也不太一样:
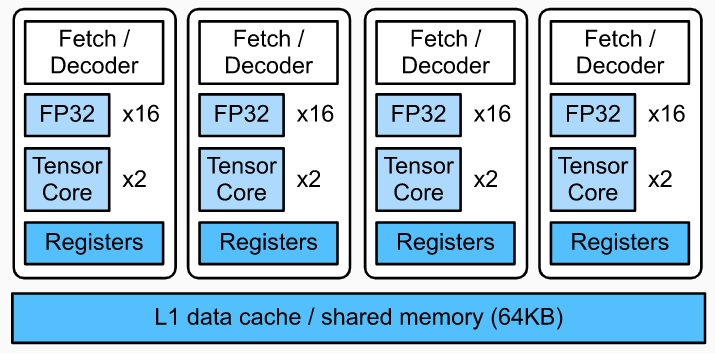
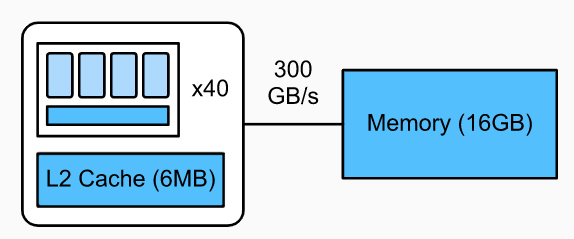
可以看到,相对 CPU 来说,GPU 多了很多可以向量化的计算单元,甚至还有 Tensor Core 可以对计算进行张量化。而且 L1 cache 可以由程序员来进行主动的控制,作为线程之间的缓存,提供了很大的自由性。 在 GPU 里面还有线程与线程块的概念。几个 thread 会统一放到一个 block 中。同一个 block 中的线程会共享同一个 L1 cache 或者 shared memory,合理的分配 shared memory 会显著减少读写时间。 在 GPU 上面优化矩阵乘法,我们可以这样写,代码来自 Dive in DL Compiler:
1 | def matmul_gpu(n): |
看起来有点复杂,其实就是 shared memory 的一些分配。从代码中可以看到,有很多 split 的操作,事实上对于缺乏经验的工程师来说,确定这些 split size 是非常困难的。 在 AutoTVM 教程中我们可以找到一个相对通用的模板:
1 |
|
对于这些 knob,有个简单进行解释的图表: 
好了,现在对 AutoTVM 已经有了一些感性的理解了。不过这个开头写的有点多,以上内容先算一篇,下一篇我们讲 AutoTVM 的具体实现。