对于目前的优化算法来说,依然存在着许多问题。但是后续的工作并不是特别多。首先可以看一下 Reinforcement Learning and Adaptive Sampling for Optimized DNN Compilation, ICML 2019 Workshop RL4RealLife 这篇文章主要谈到的问题是两点:1. 开发一个更有效的搜索算法(相对于 AutoTVM 的模拟退火) 2. 减少硬件测试的时间。从这篇文章的实验结果来看,第一个目标基本上没有达成,第二个目标完成的还不错。这个第二个目标也是我认为的之后优化的核心问题。 文章的整个框架如下图,主要贡献是两个蓝色的部分——基于强化学习的搜索和自适应采样。
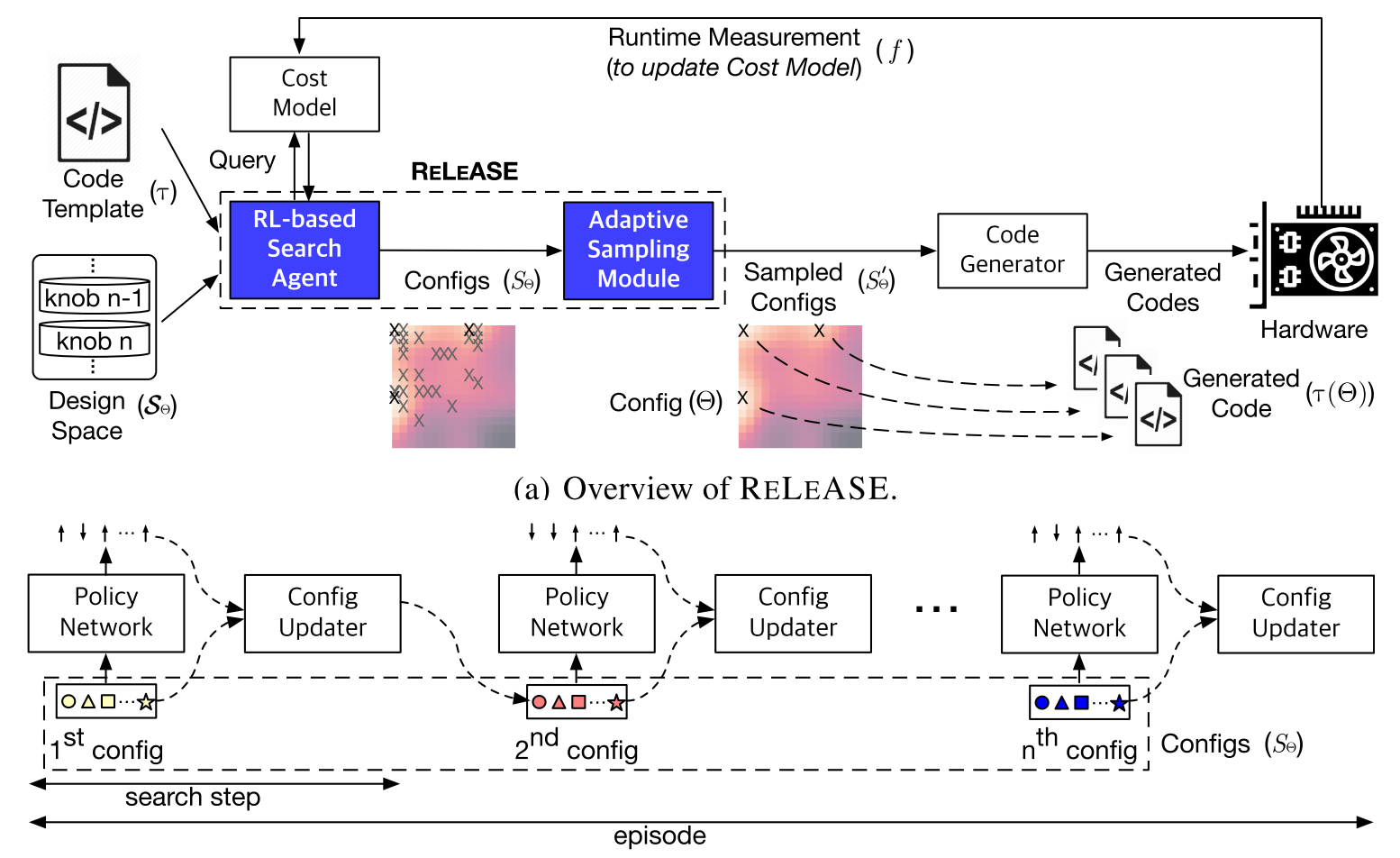
整个过程不是很复杂,这个强化学习其实就是用来代替模拟退火的。迭代数次 Policy Network,输入是一个当前算子的 config,也就是之前说的 schedule,输出是对 config 的上下调整。强化学习要从环境里面获取代价,这个代价其实就是从 cost model 里面预测出来的每个 config 的运行时间,再用 PPO 的方式去训练 Policy Network,这个强化学习套路感觉非常的强行,最后效果也一般般。 然后对所有的 config 进行自适应采样,只对采样出来的 config 在硬件上测试实际的运行时间,然后将采样出来的 config 用于 cost model 的训练。这个所谓的自适应采样其实非常简单,就是对所有 config 做一个 k-means,然后采样每个centroid。
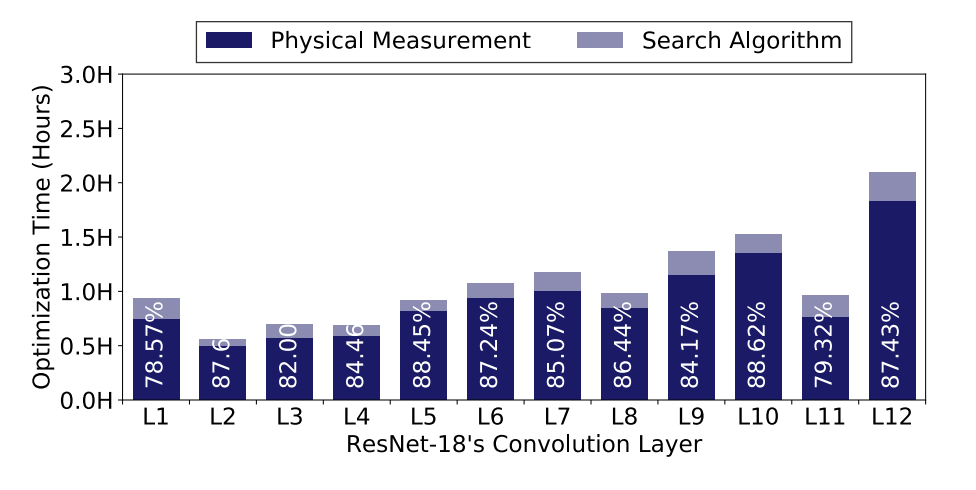
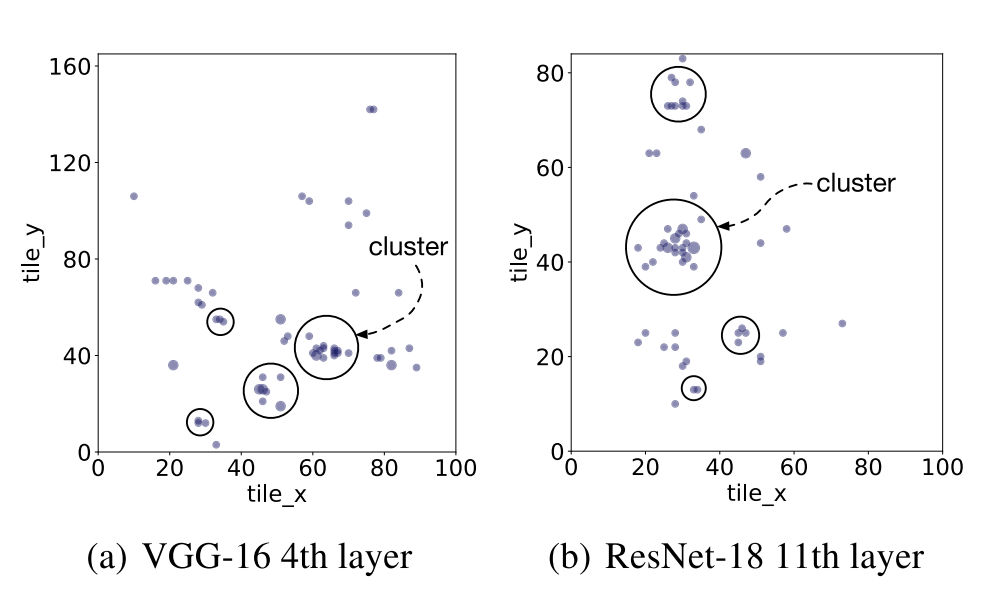
从上面两个图可以看出,第二步自适应采样的动机还是比较强的。因为对于 AutoTVM 来说,大量的时间都用于在硬件上测试算子的运行时间,而且相似的算子 config 确实很多,所以通过聚类然后采样的想法确实比较直接。最后的加速效果也不错:
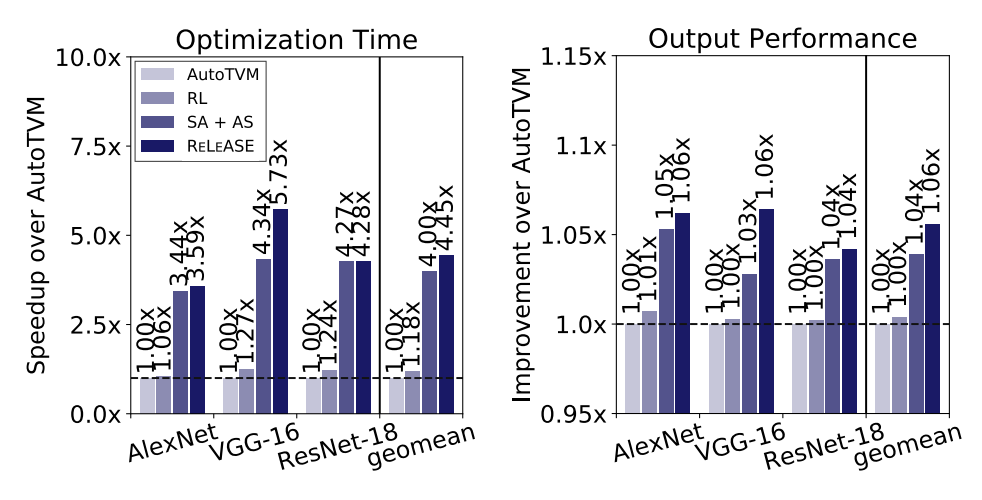
通过结果可以看出来,虽然最后的加速效果很不错,但是对于结果的优化程度几乎没什么变化。说明第二步自适应采样很有效,但是第一步强化学习其实没什么用。讽刺的是这个进的还是 RL4RealLife Workshop... 对于 AutoTVM 来说,目前最主要的问题还是 tuning 的时间过慢。所以 AutoTVM 只能用于 inference,不能用于 training。因为你 tuning 的时间很有可能就比 training 的时间长了...
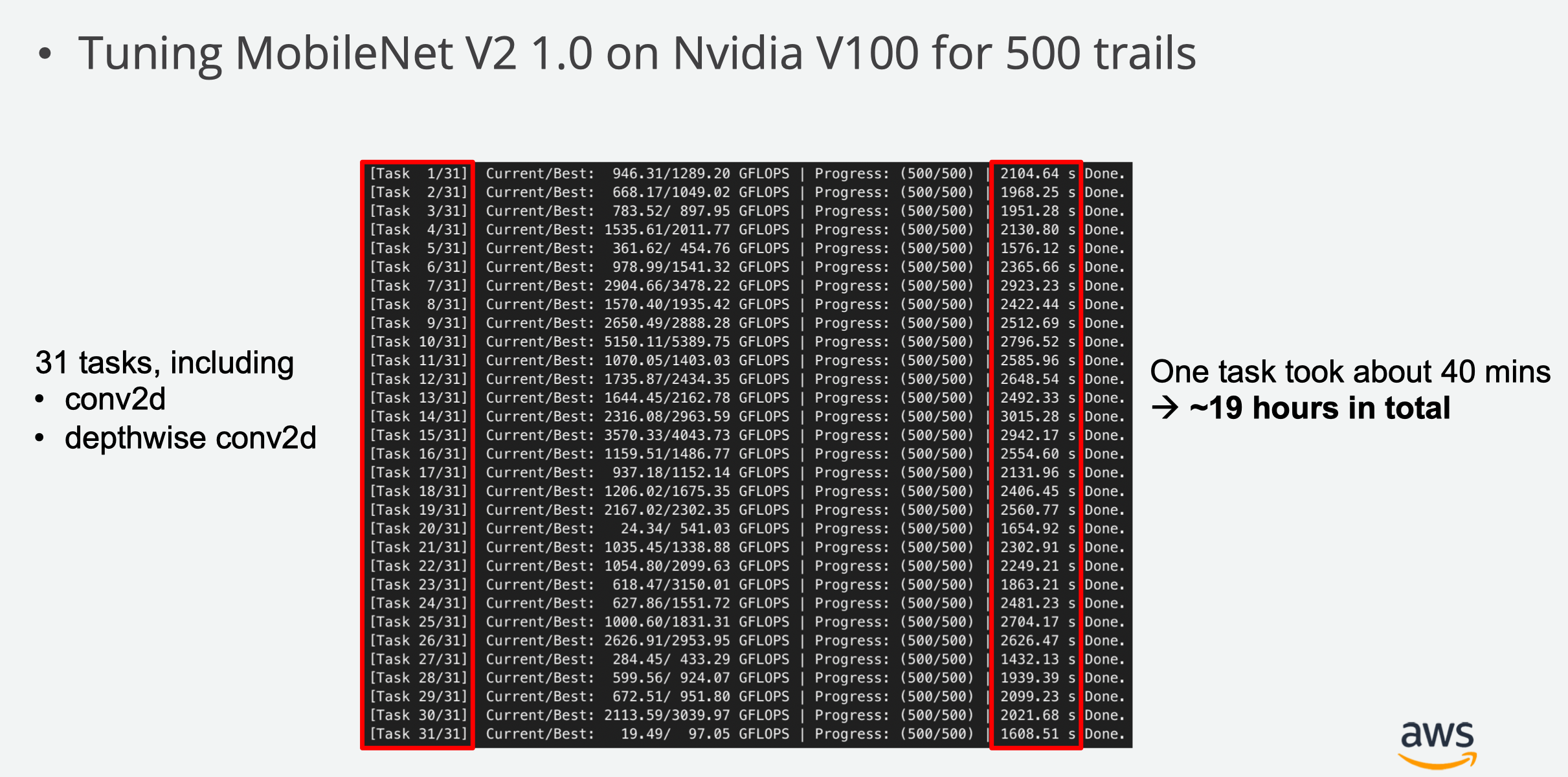
从上面的图中可以看到,tuning 一次 MobileNet,在 V100 上面都要花差不多 19 个小时,非常缓慢。在我们实验室这种显卡上面,大概就要两到三天了。
在 2019 年 12 月 5 日结束的第二届TVM与深度学习编译器会议上面,也有一个思路类似的 talk。是来自 AWS 的 Improving AutoTVM Efficiency by Schedule Sharing。跟上面的那篇文章非常类似,也是用聚类去优化 AutoTVM。 从上面的图中可以看出,对于每个从模型中抽取的 task,都要进行 turning。这个工作的动机是,如果一个 schedule 在一个 conv2d 上面效果良好,那他在另一个 conv2d 上面的效果应该也还不错。这意味着可以利用一些有代表性的任务来 turning,然后把该任务的 schedule 直接迁移到相似的任务上面去。这里的距离计算方式是 turning space 的重叠比率,然后利用这个距离来聚类。
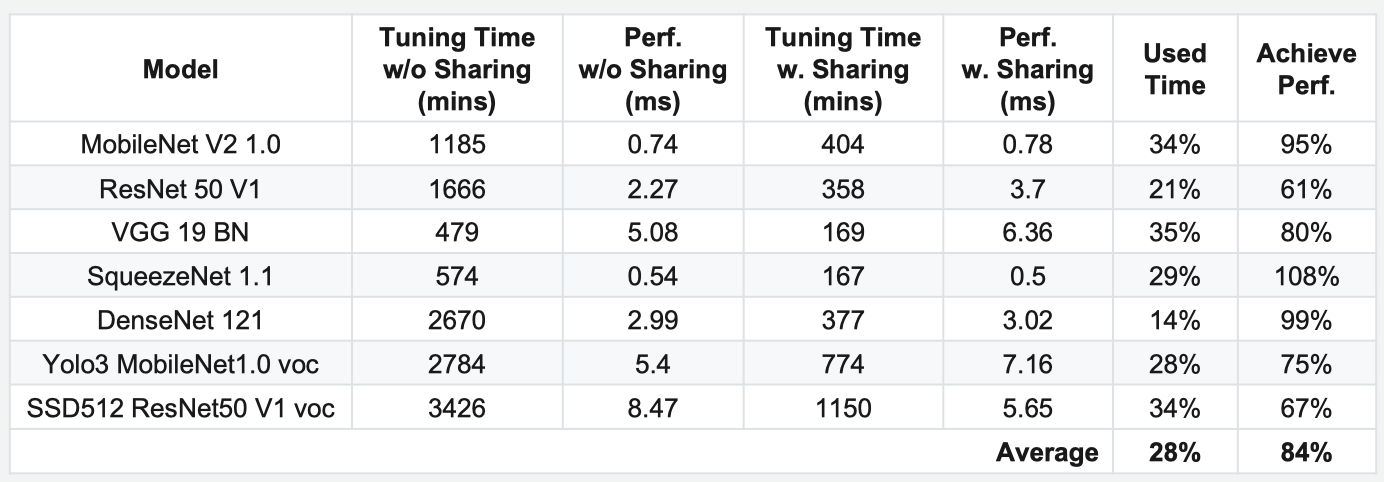
从上面这个图中可以看出,Schedule Sharing 可以在平均 28% 的调整时间里获得 84% 的加速效果。相关讨论和 PR 在 github issue 上面可以找到。 新的搜索方法,还有一篇 Compiler-Level Matrix Multiplication Optimization for Deep Learning, arXiv。这篇文章只把问题限制在了调 MM 的 tile size 上面,整个搜索空间与问题范围缩小了很多,而且去掉了 cost model,直接用强化学习来指导搜索,其实就相当于有一个很慢但是很准确的 cost model,跟前面讲的第一篇非常相似。(虽然这个 cost model 可能比 XGB 慢了差不多 1000 倍吧 XD) 总结一下上面的几个工作,几乎都是采取了一些很简单的做法,就对 AutoTVM 的整个 turning 时间起到了巨大的提升。说明这方面研究的潜力还是非常大的,如果能压缩到五分钟 turning 完一个网络,说不定就可以用 AutoTVM 来帮助 training。(当然现在来看还都是空谈,因为最好的工作也就是四到五倍的压缩效率,从两天变成半天)
说完了对搜索方法和训练采样方法的一些魔改方法之后,下面应该要说一些对于 AutoTVM 的核心 cost model 的魔改方法了。 目前对于 cost model 的研究集中于 GNN 上面,第二届TVM与深度学习编译器会议上面有一个 UW 的 Talk,题目是 Graph Convolutional Cost Models for TVM ,还有一篇 Simulating Execution Time of Tensor Programs using Graph Neural Networks,ICLR 2019 workshop at Representation Learning on Graphs and Manifolds。这两个工作基本是一样的,都是用 GCN 去优化 cost model。然而怪异的是两个工作的结果都是跟 XGB 在一个类似于估计运行时间的数据集上面的对比,没有最后 end-to-end 的效果提升。 两个工作都是用 AST 建图,大概长这样:
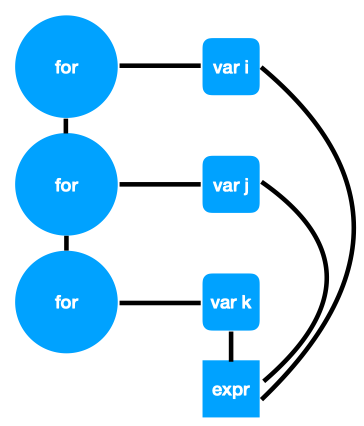
然后用 GCN 求一下 embedding,然后把所有 embedding 都平均一下,然后接个 MLP...
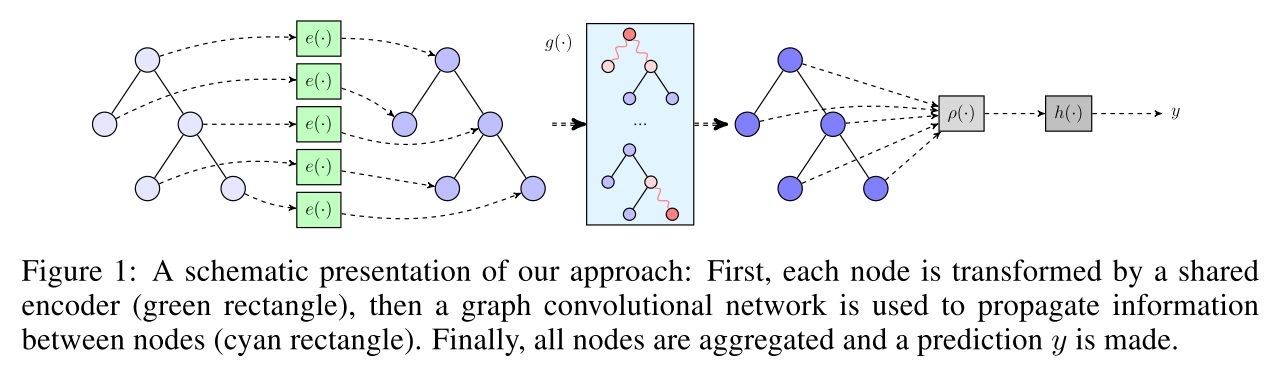
然后没了。
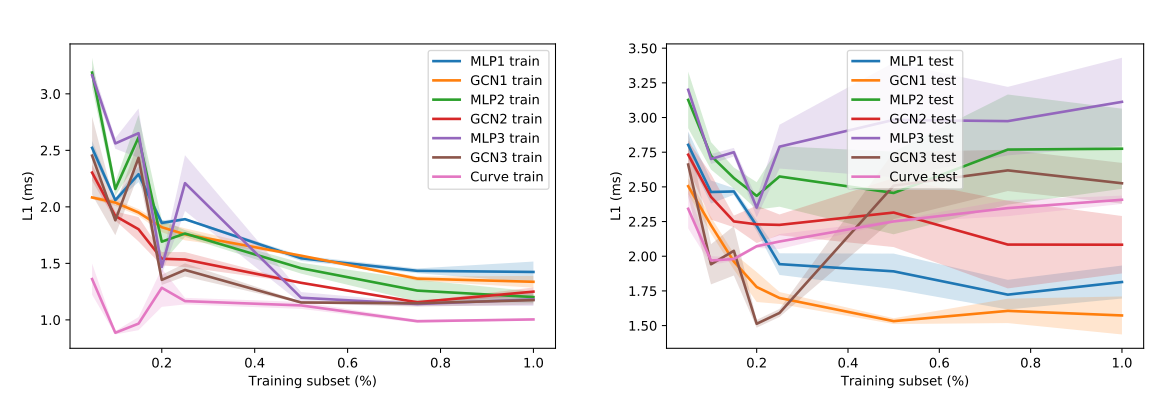
这效果看起来其实也就那样,而且还没测 end-to-end 的性能,估计是实在不能看。