关于 Source Code 的 learning 其实已经有很多工作了,每年的顶会中也有很多这个方面的文章。其实针对 Source Code 的 learning 可以算是 NLP 的一个子领域,因为 Source Code 本身就是就是程序员之间交流的一种语言。因为 Code 是一个结构化数据,存在着语义信息与语法信息,所以相比于自然语言来说,Source Code 是适合于 GNN 大显神威的领域。
Learning to Represent Programs with Graphs. ICLR 2018 是 GNN 在 Source Code 中运用的比较早的工作,质量也蛮高。 首先定义一下这篇文章要解决的两个问题: 第一个问题叫做 VARNAMING,就是在一段代码中有个匿名的变量,然后要通过这个变量在代码中的行为来对这个变量命名。 第二个问题叫做 VARMISUSE,类似于程序填空,预测一个程序中空缺的 token 是什么。通过这个任务,可以发现代码中一些 misuse 性质的 bug,举例如下:

当然,对于第二个任务来说,合法的解可能有好几个,就跟考试的程序填空中有好多正确答案一样。 根据文章的标题,可以想象文章的内容就是把 program 建成一个图,然后在图上面跑 GNN。文章中所采取的的 GNN 是 GGNN (Gated Graph Neural Networks),可能是因为这个 GGNN 比较适合 program 建的图,所以很多后续工作采用的也是这个方法。 图定义为\(G=(V,E,X)\),其中\(V\)是节点、\(X\)是特征,\(E=(E_1,...,E_k)\)是边的集合,边有\(k\)种。 每个节点状态为\(h^{(v)}\),初始状态就是\(x^{v}\)。跟传统的 GNN 一样,每个节点会向外发送\(k\)的类型的消息\(m_k^{(v)}=f_k(h^{v})\),然后每个节点聚合邻居的消息\(\widetilde{m}^{(v)}=g(\{m_k^{(u)}\}\mid{(u,v,k)\in E})\)。 特殊之处在于更新\(h^{(v)}\)的方式,GGNN 用的是 GRU 单元来更新特征向量。\(h^{(v)}=GRU(\widetilde{m}^{(v)},h^{v})\)。这样可以捕捉到一些较远的点对该点的影响。 在该论文中,\(f_k\)是一个线性函数,\(g\)是个简单的求和。 这篇论文中比较炫酷的部分是建图。首先一个程序,自然对应一个 AST,这个 AST 的叶子节点是程序中的 token,中间节点对应着 BNF 的中间节点。因为 GNN 捕捉不了树的儿子的顺序,所以要加一个 NextToken 边来把 token 都串起来:
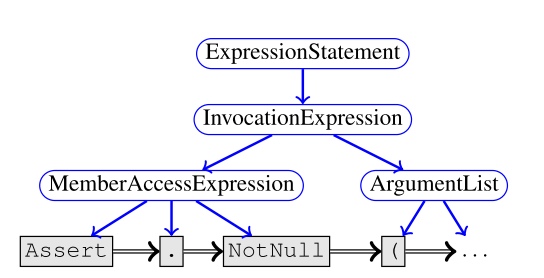
另一方面,我们要捕捉程序的 Data-flow 信息。对于每个变量来说,上一次 read 的位置,连接一个 LastRead 边,因为有分支结构存在,这种边可能有多条。同样,上一次 write 的位置,连接一个 LastWrite 边。有赋值语句存在的时候,左右两边的语句要连接一个 ComputedFrom 边:
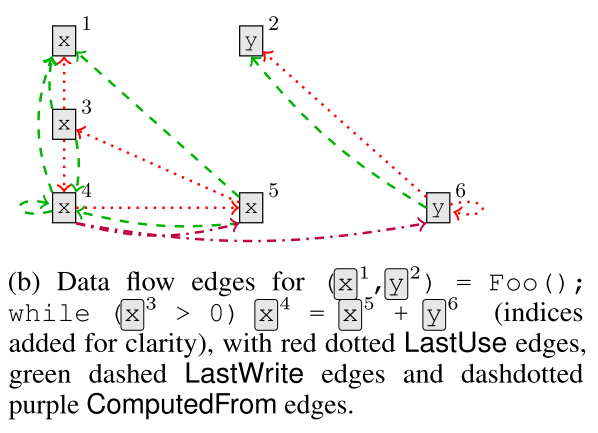
作者还加了很多乱七八糟的边,比如用 LastLexicalUse 来把所有同一个变量的调用都串起来。return 后面接的变量也会通过 ReturnTo 边连接到方法的声明上。对于形如 Foo(bar) 和 Foo(InputStream Stream) 这样的方法调用与声明,bar 也会连接到 stream 上。最后,对于 if(x>y){...x...}else{...y...} 这样的语句,x 向条件节点连一个 GuardedBy 边,y 向条件节点连接一个 GuardedByNegation 的边。 最后再把所有反向边都加入,也就是形成一个无向图。这个图就处理好了。 这篇文章做实验用的是 C# 的一些项目。跟 Python 这种垃圾语言不一样,C# 每个变量是有固定的类型信息的,这种类型信息显然是可以运用的。作为一个高贵的 OOP 语言,C# 的类型还是有层级的。对于一个类型\(\tau\),有一个 embedding 函数 \(r(\tau)\)。因为这个类型具有层次结构,所以可以搞一个集合\(\tau^{*}(v)\),里面具有\(v\)本身的类型和\(v\)所有的父类型的 embedding,然后对这个集合每一维度取个最大值,作为变量\(v\)的类型特征。可以用类似 dropout 的方法来进行优化。 变量\(v\)还具有变量名,可以把变量\(v\)的变量名进行分词,分出来一堆 subtoken。这些 subtoken 的表示取一个平均作为变量名的特征。把变量名特征跟类型特征连接起来,得到每个节点的最初表示。 整个网络的结构有了,下面就是用这个网络来解决 VARNAMING 跟 VARMISUSE 了。 对于 VARNAMING 来说,可以把要命名的变量名替换为 SLOT token。然后跑一遍 GNN,对于每一处变量的表示取个平均值。这个值作为一个 GRU 的输入,来生成一堆 subtoken 作为变量名。这样就转变为一个 GraphToSeq 的问题。 VARMISUSE 的问题会相对复杂一点。首先也是把目标位置\(c(t)\)替换为一个匿名的 SLOT 变量。正常连边的时候,变量相关的变量应该都不会连接到 SLOT 变量上。然后将候选集中的每个变量\(v_{t,v}\)加入到这个图中,并连接好变量相关的边。在这个图上跑 GNN,可以得到\(h^{SLOT}\)和\(h^{v_{t,v}}\)。最后通过\(argmax_v W[h^{SLOT}, h^{v_{t,v}}]\)来找到正确的变量。
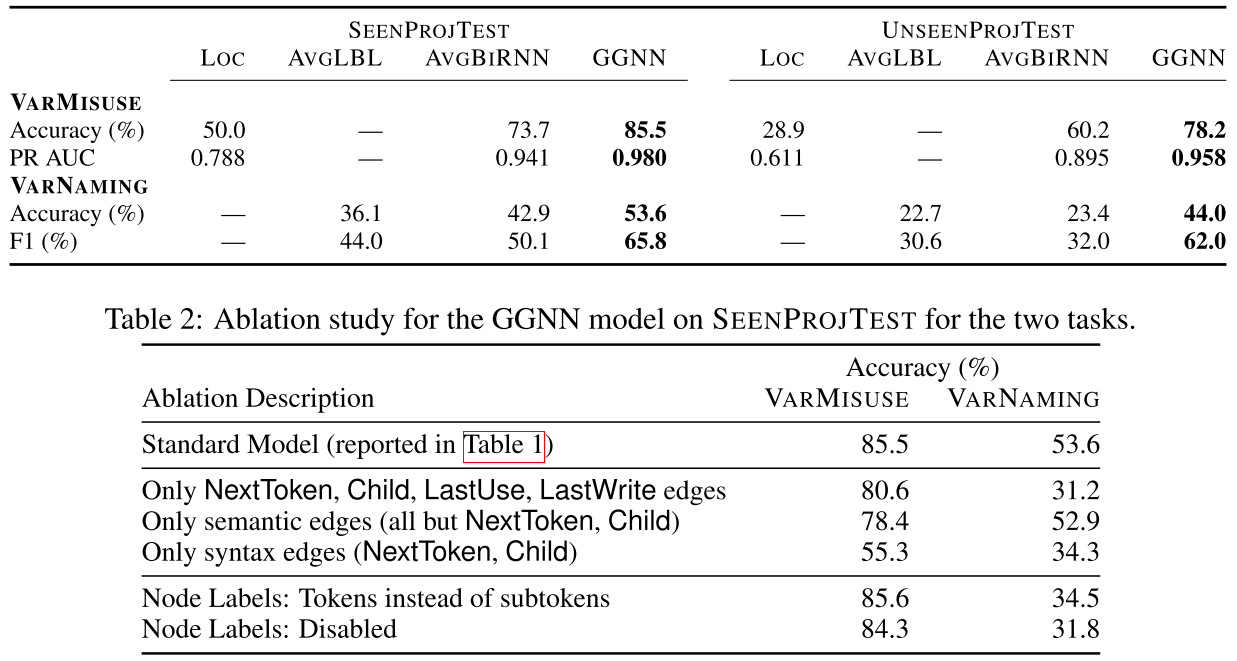
相比一些简单的 baseline,这个方法效果提升巨大。值得注意的是,加入的各种边和节点的 embedding 也非常的 make sense,对最后的效果很有帮助。