这篇讲一个基于上一篇的改进工作。 在 Source Code 中,因为程序员的变量命名通常来讲都比较诡异,所以存在着比较严重的 open vocabulary 问题(也叫作 Out of Vocabulary)。比如一个变量名叫做 LianlianInput,因为这个 Lianlian 不在词汇表里面,VARNAMING 的时候就根本不会输出这个 subtoken,对最后的效果有比较严重的影响。
Open Vocabulary Learning on Source Code with a Graph-Structured Cache. ICML 2019 这篇文章就致力于解决代码中的 open vocabulary 问题,而且是通过 GNN 来解决,与我们的主题十分契合。 整个建图过程跟之前的工作非常类似,只是多了 Graph-Structured Cache Node:
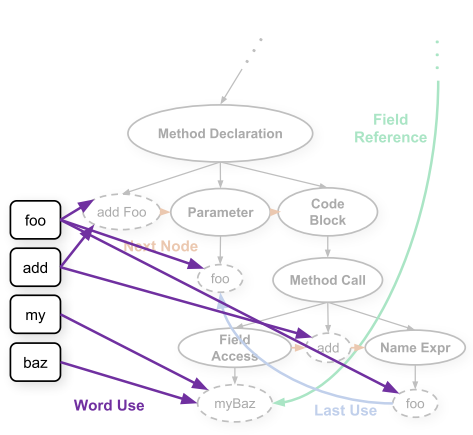
其实也是先分词,然后相同的词搞一个节点而已。初始的特征是节点名字特征跟Cache节点类型本身有个特征进行拼接。节点名字特征用 CharCNN 来计算。 建图层面还是比较简单的,这篇文章主要的贡献之处在于利用 GSC 节点来解决 open vocabulary 的问题。解决的方法在于修改 GNN 最后一步\(y=g(\{h_v^t\})\)中\(g\)的计算方式,灵感来自于 Pointer Network。为了方便之后理解,先简单叙述一下啥是 Pointer Network。 这个 Pointer Network 本来是做组合优化的,最开始用来解决凸包问题。凸包问题我们都知道,输入一个点集,输出一个凸包。但是这个输出的范围其实是跟输入相关的。Pointer Network 用了很简单的机制解决了这个问题:
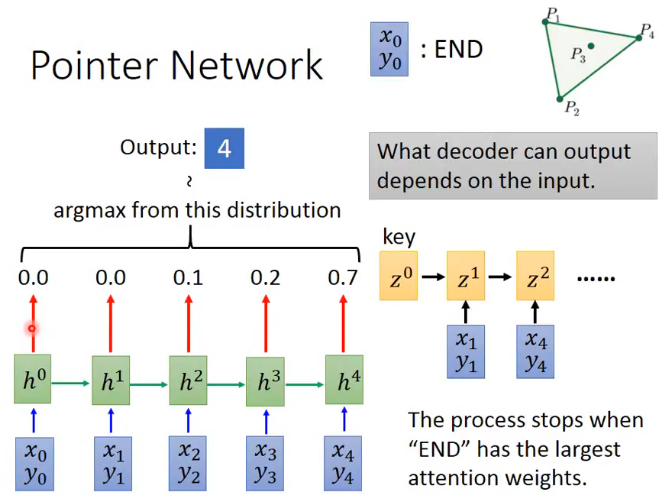
在传统的 attention 中,都是 encoder 和 decoder 的 hidden layer 算个权重,然后组合一下 encoder 的所有权重输入到 decoder 中。这里的输出就直接把 attention 的最大权重作为其中一步的输出,并且输入到 encoder 中继续形成新的 hidden layer。 下面就看看如何利用 GSC 解决 VARMISUSE 的问题。在前一篇文章中,这个 VARMISUSE 问题解决起来其实还是比较复杂的。这篇文章用 Java 项目作为数据集。因为 Java 跟垃圾语言 Python 不一样,是一个要先声明后调用的语言。所以对单独语法槽的预测,都可以变成一个 Pointer Network 问题,指向现存的变量节点。对于 GGNN 来说,简单按照\(y=\sigma(f_1(h_v^t,h_v^0)\odot f_2(h_v^t))\)来计算一下 attention 权重(其实我不太懂这个 attention 为什么跟槽的 embedding 无关,可能是因为 GGNN 论文里面的 readout attention 就是这么做的),挑其中最大的几个作为输出即可。
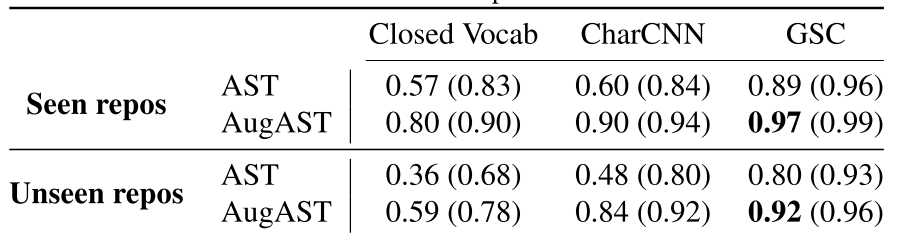
可以看到,加上 GSC 之后效果有一定的提升。 解决 VARNAMING 的思路跟 Pointer Sentinel Mixture Model 非常相似。Pointer Sentinel Mixture Model 就是把纯 attention 求出来的 open vocabulary 分布和正常 attention 求出来的 close vocabulary 分布加到一起,来预测要产生的序列:
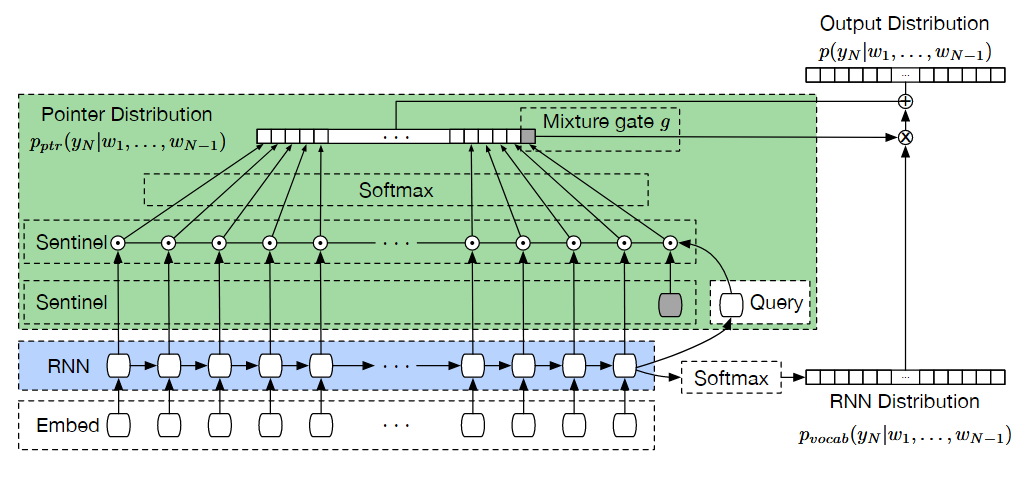
这个 open vocabulary 和 close vocabulary 组合的权重利用一个名为 sentinel 的虚拟输入的 attention 值来计算。 对于 VARNAMING 来说,也是按照上一篇文章的方法建图,对于所有要命名的变量 embedding 取一个平均值,然后作为输入放到 GRU 中。close vocabulary 的分布按照正常的方式产生,Pointer Network 的 attention 权重就是把每个 GSC 或者 sentinel 的 embedding 输入到一个线性层,然后跟 hidden layer 点积一下接一个 softmax。最后的公式就是:\[P(w|h)=P_{graph}(s|h)P_{graph}(w|h)+(1-P_{graph}(s|h))P_{vocab}(w|h)\]
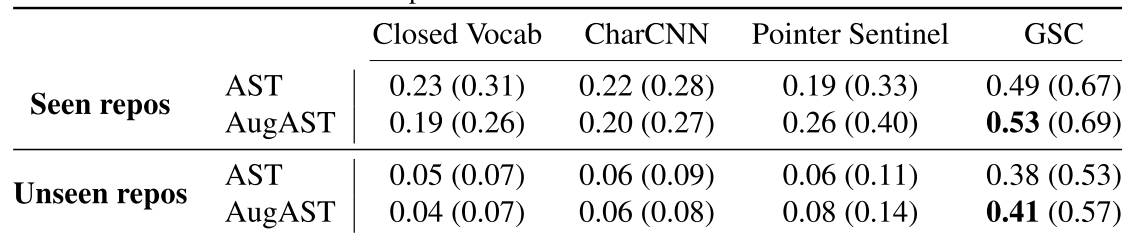
可以看出,实验效果提升巨大。可能看起来还是不怎么样,但是要考虑到这个问题的难度,做成这样就不错了。