在几个月前,试图开了一下MIT 6.828的坑,但是因为各种原因,只做了lab1就搁置了。前几天突然在知乎上看到了二十八画生征友:一起来通关6.S081/6.828吧~,发现这个MIT 6.S081是MIT 6.828的简化版,而且梯度更加的平滑。 之前的一段时间都因为各种事情,忙的飞起。最近正好有一段空闲时间,希望可以在一个月内通关MIT 6.S081。
一个比较好的参考资料。
首先按照tools配环境,因为我用的是Ubuntu 18的虚拟机,所以需要自己手动去编译riscv-gnu-toolchain,编译的过程其实非常简单,但是下载的过程非常痛苦。这边有个老哥直接把riscv-gnu-toolchain放到百度云盘上了,这样下载就会快很多而且不容易中断。
Lab-1 Utilities
Lab1其实就是实现一些shell指令,做实验前一定要把xv6 book的第一章通读一遍,非常关键!!!
sleep & pingpong
相对简单,略过。这个pingpong我是用两个pipe从两个方向传输的。
primes
一个非常风骚的多进程筛法。主要流程如下图:
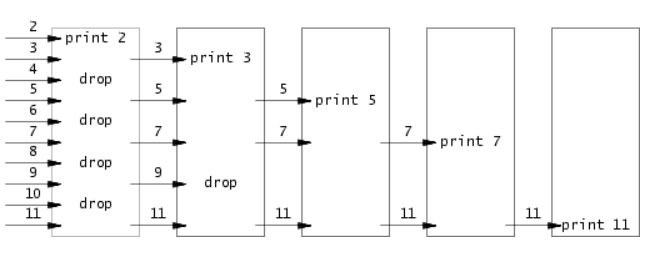
其实就是每个素数开一个进程,多个进程形成一个pipeline。按顺序输入数字,如果一个数被前面所有进程漏掉,那他显然是一个素数,就再开一个进程进入pipeline。
1 |
|
我直接暴力的用了一个p数组,代表每个进程向下传输所需要的pipe。一个素数的进程的pipe就直接使用p[素数]的数组就好了。因为fd空间不够35以内的素数开满,所以要管理fd,这个地方要小心处理,我因为close了一些回收过的fd错了好几次。
一个值得注意的地方是read前的close(p[from][1]),这个bug我也卡了一小会儿,这里直接引用xv6 book中的原文:
If no data is available, a read on a pipe waits for either data to be written or for all file descriptors referring to the write end to be closed.
没错,是all file descriptors都要close才行,不然read就会一直挂在那里,导致死循环。
find
这个本身其实挺复杂的,幸好ls指令已经写好了,所以直接抄就完事儿了。
xargs
这个理论上其实很简单,就是解析标准读入进来的字符串,先按照'\n' split一下,再按照' ' split一下,最后拼成argv就好了。但是有个地方非常坑爹,我最开始的时候,从标准读入读字符串,简单写成了这样:
1 | buf_size = read(0, buf, (sizeof buf)) |
这么写完之后,make grade大概五次会错一次,非常诡异。一般来说这种情况都是多进程出了问题,这时再掏出xv6 book的原文:
The child process creates a pipe to connect the left end of the pipeline with the right end. Then it calls fork and runcmd for the left end of the pipeline and fork and runcmd for the right end, and waits for both to finish.
一个pipe的左右指令是多进程,所以当左边指令输出,右边指令输入的时候,应该写成阻塞式:
1 | while ((buf_size = read(0, buf + offset, (sizeof buf) - offset)) != 0) { |
我跑了十次,全都通过了testcase。
Lab-2 System calls
这次实验是实现两个系统调用trace和sysinfo,感觉在实现上没什么好说的,两个任务都比较简单。这里想重点总结一下整个xv6的boot和system call的流程。
首先讲讲boot的整个流程。我们的整个实验环境是搭建在RISC-V上面的,在RISC-V中,CPU运行的指令分成三种模式:machine mode, supervisor mode和user mode。最开始的时候,CPU是处于machine mode的。开机后,CPU运行boot loader中的指令,把整个kernel都给load进来。然后进入entry.S:
1 | _entry: |
entry.S的任务就是初始化stack,然后开始call start.c:
1 | void |
在RISC-V中,mret、sret和uret分别用于从machine、supervisor和user模式中的trap返回。这里调用的是mret,其实就是从machine mode返回到supervisor mode。
在main.c中,userinit函数首先allocproc()出来第一个用户进程,然后执行initcode.S中的指令,这个指令其实就是调用SYS_exec执行init.c:
1 | .globl start |
在init.c中,系统生成一个名为"console"的device,并重载标准输出跟标准错误输出到这个device上,之后启动sh.c,shell启动,正式进入操作系统。
然后再讲讲整个system call的流程。这里我们可以用作业中的Sysinfo作为例子。
Sysinfo的功能是统计一下当前系统的剩余内存和已经使用的进程数量,并把这两个参数组装成一个结构体,传回给用户。这里就要分为三步,首先在user mode进行system call,进入supervisor mode,然后统计两个信息,最后system call return需要的信息回来。
我们要在user mode中调用这个sysinfo函数,但是因为这是一个系统调用,肯定不能在user mode里面实现,所以需要一个user mode的函数与supervisor mode的system call的绑定。具体到代码中,其实就是user/usys.pl中会有个entry("sysinfo"),这个语句会生成一段汇编代码:
1 | sysinfo: |
这个ecall指令会让我们进入supervisor mode并运行SYS_sysinfo函数。那么问题来了,我们看到系统调用的参数都是(void)的,并且我们当前user mode的各种寄存器要怎么保存呢?要解决这个问题,首先要知道ecall指令到底干了什么,在xv6 book中,是这样说的:
The ecall instruction traps into the kernel and executes uservec, usertrap, and then syscall, as we saw above.
uservec是一段汇编,主要是保护当前的user mode现场,将user进程中的寄存器数据放到TRAPFRAME中,同时加载kernel的页表。然后调用trap.c/usertrap()。
在trap.c/usertrap()会进入syscall(void)函数,syscall(void)会根据a7寄存器中的值调用对应的system call,system call参数的传递通过TRAPFRAME中的a0-a5寄存器,运行过后的返回值放到p->trapframe->a0寄存器中。
然后调用userret,也是一段汇编代码。userret会恢复user mode的页表,并且从TRAPFRAME中恢复过去的寄存器,这样就完成了一次系统调用。但是我们发现,system call并没有传递任何值给user mode,其实system call的返回值要通过copyout函数,直接写入该进程在user mode能使用的地址中。
Lab-3 Page tables
这个实验相对复杂,要比较清晰的理解页表才能顺利的完成。
首先,我们要了解页表是个什么东西。其实页表就是个(key, value)的pair集合,key是虚拟地址,value是物理地址,在程序使用的地址跟计算机实际运行的内存地址之间产生一层隔离关系。
这种隔离关系的好处是,不同进程之间无法直接访问对方的变量,恶意程序也无法破坏整个操作系统,只能破坏自己的进程。
其次,还可以使得物理上不连续的、不从0开始的物理地址变成连续的、从0开始的虚拟地址,方便内核做统一的内存管理,而不是每个进程自己乱管理。
Print a page table
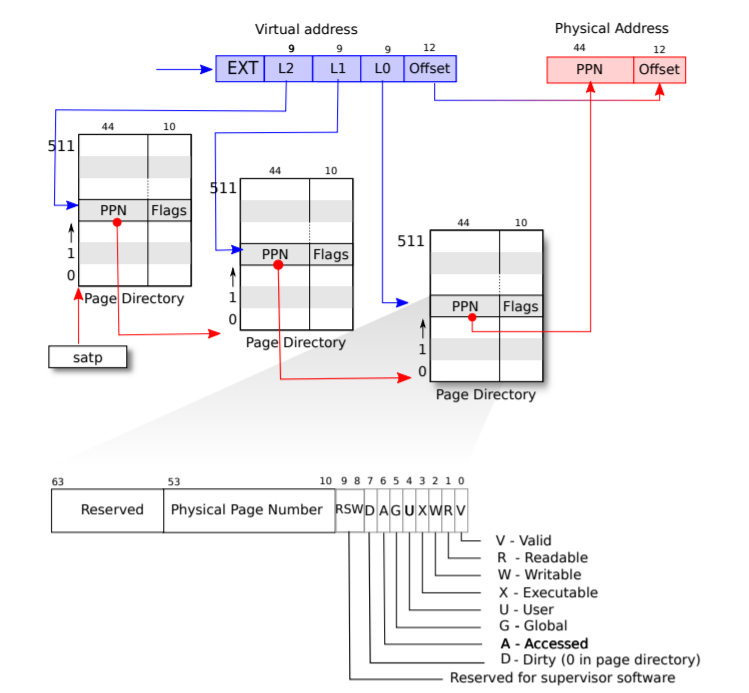
完成打印页表的任务,只需要理解这个三级页表的架构就好了。从图片可以轻松了解这个数据结构,但是作为一个kv系统,为什么要这么设计呢?
其实很简单,如果页表只有一级,那就是空间换时间,一个巨大的桶存着页表。如果页表级数特别多,那访问时间就会很慢。三级页表就是个设计上的trade-off,而且这么设计,每一级页表就是一个page的大小,我觉得代码会更加规整。
判断一个页表的内容是否合法,其实就是对应一些掩码的位置,核心逻辑如下:
1 | void |
A kernel page table per process
这个环节又涉及到一个新的问题:用户级页表和内核级页表。
在上个环节我们已经知道,页表的主要功能是为了控制访问权限。那么理论上来说,每个用户级进程都要有自己的页表,从而只能访问自己的地址,不能访问别人的地址。内核既然是随便访问,那么用一个固定不变的内核页表就好了。所以在用户级进程与系统调用之间涉及到一个页表切换的问题。
kernel page table per process要求我们实现一个新功能,内核页表不再是全局的,而是每个进程独立的。这个任务分成两步:建立每个进程自己的内核页表、实现页表切换。
首先看一下内核页表在哪里进行了改动,我只发现了两个地方,一个是kvminit(),将低地址的IO device和trampoline映射到页表中。第二个是procinit(),这里声明了进程池中每个进程的栈空间,并跟内核页表进行绑定,方便内核从每个进程的栈中获取参数之类的。
那这个建立每个进程自己的内核页表就很简单的,先把kvminit()里面的东西都映射到每个进程的内核页表中,再绑定自己进程的栈就可以了。
实现页表切换分为两步,将页表写入satp寄存器,然后用sfence.vma刷新TLB,所以页表命中是完全靠硬件,页表缺失会引起中断,需要操作系统跟硬件的配合。在scheduler()中就可以进行页表的切换,需要注意的是,进程的内核部分运行结束后要立刻把页表切换成全局的内核页表。
Simplify copyin/copyinstr
经过上一轮的准备之后,我们可以简化copyin/copyinstr的流程。copyin是一个系统调用,要把进程中内存的一些东西copy到内核中,这里的问题在于,系统调用传入的地址是一个虚拟地址,在没有进程中的用户页表的情况下,我们无从得知该虚拟地址对应的物理地址的位置。所以在xv6中,copyin的函数签名为:
1 | int copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) |
这里问题的关键是,因为内核页表是全局的,我们无法修改内核页表,让硬件帮助我们完成虚拟地址到物理地址的转换,所以要先进行一步软件层面的转换,然后通过内核页表的直接映射的性质去完成系统调用。当然,我们在上一个环节实现了每个进程自己维护的内核页表,所以我们可以将虚拟地址的映射加入到自己维护的内核页表中。
这里为了保持一致性,要小心的修改,在fork(), exec()和sbrk()的函数中,都有对虚拟地址映射的修改,主要增加或是改变对应内存大小。
这里其实有个问题,就是内核页表是采用直接映射的方式。也就是在映射用户的虚拟地址之前,低位其实已经映射一些内容了,这就会导致remap。一方面要调整我们的函数去忽略remap,另一方面lab指导中告诉我们,PLIC寄存器之前的空间都可以随便映射。
Lab-4 Traps
该实验系统的总结了trap的流程,其中大致的流程我们在上一篇文章lab2中都已经叙述过了,通过lab4,我们会对整个流程理解的更加深刻。
trap来自三种情况:syscall对ecall的调用、程序运行的错误、设备中断(比如时钟)。当中断发生时,我们会自动运行一段运行好的程序,当然,kernel中断跟user中断运行的程序应该是不同的,所以要用一个寄存器储存这段程序的位置。user中断的过程会相对复杂,因为user process会发生各种事情,所以我们就从user中断讲起。user中断运行的位置就是trampoline中的uservec。
uservec的功能我们lab2中已经分析过了,主要是切换页表跟保护现场两个功能。因为要使得切换页表后,trampoline中的程序在用户态和内核态都能运行,所以trampoline在内核页表和用户页表中要完全相同。
之后在usertrap中判断trap的类型,systemcall就去准备systemcall,时钟中断就去修改process的状态,错误就直接kill整个process,之后再调用userret将之前保护的现场还原回去以及将页表改回用户页表。
内核的trap跟用户的trap原理相似,但是一个很重要也很繁琐的细节就是,当user trap进入内核态的时候,内核也有可能继续trap。这就要求我们在进入user trap的时候,要准备好所有kernel trap可能用到的东西,以及保存kernel trap可能破坏的位置,方便kernel trap结束后进行恢复。
RISC-V assembly
作业让我们熟悉一下RISC-V,群里大佬们推荐了一本包云岗翻译的RISC-V的教材,可以用来查询。
询问了一些简单的RISC-V的问题,但是要注意,他的编译器是默认开优化的,比如第一问:
Which registers contain arguments to functions? For example, which register holds 13 in main's call to printf?
1 | printf("%d %d\n", f(8)+1, 13); |
看指令,这个13可以理解是什么,但是这个12是哪来的。再一看f跟g函数,估计是太简单被直接常量折叠了,那我们就把编译选项加上-O0再来一遍。
1 | printf("%d %d\n", f(8)+1, 13); |
可以比较清楚的看出来,第一个f(8)+1在a1寄存器中,第二个13在a2寄存器中。
Backtrace
这个任务就是输出调用栈信息,这些任务都存在stack中,stack结构在slide中可以看到:
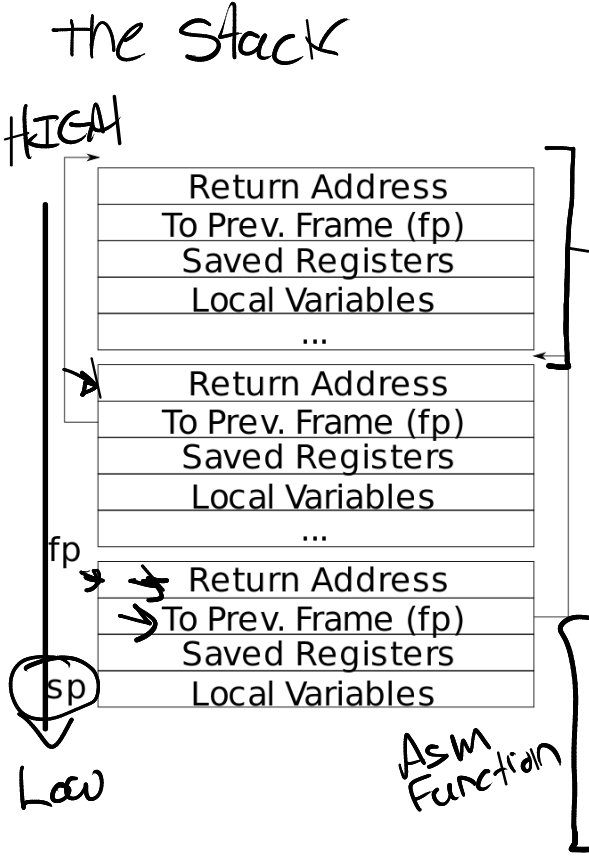
其中初始的frame-pointer值,实验指导已经给出了代码。那问题就在于什么时候停止往前回溯。其实只要frame-pointer等于PGROUNDUP(fp)就可以跳出循环了。因为最浅层的那个调用既没有frame-pointer,也没有return address。
1 | void |
Alarm
这个实验难度较大,让我们实现一个syscall,可以监控cpu在该进程上的运行时间。单独监控运行时间其实比较简单,大致思路就是在process里面加个变量,当产生时间片中断时,就把这个变量++,然后输出。但问题是,实验让我们完成的函数是sigalarm(int ticks, void (*handler)())这种形式的。每次经过ticks时间片,就调用一下handler函数。
我们根据实验材料中的提示,可以简单得到这样一个思路:
1 | // give up the CPU if this is a timer interrupt. |
这样当调用usertrapret()之后,会自动运行handler位置的程序。但是当我们运行test程序之后,发现第一次监控输出之后,后面的程序会发生混乱。
简单分析一下,可以发现,我们回到handler之后,并没有再回到原本process运行的位置。这样就会产生补救的思路,先把trapframe存起来,然后当handler运行结束后,通过另一个系统调用,将trapframe恢复:
1 | p->timer ++; |
因为有个slow_handler()测试点,暗示我们handler运行的过程中,计时功能应该关闭,所以我们要加一个p->ishandle变量来把门。
Lab-5 Lazy Page Allocation
该实验主要是对sbrk的修改,就是当一个process要求操作系统分配更多内存给他的时候,并不直接进行分配,而是当process真的访问到该内存的时候,再进行分配,整个过程都是由缺页中断进行驱动的。
Eliminate allocation from sbrk()
非常简单,只要修改p->sz就行了,不需要进行任何其他操作。
Lazy allocation
通过这个case其实也非常简单,我感觉怎么写都能过,我在写这个的时候错了好几个地方,都成功通过echo hi了。
原理也比较简单,就是在缺页中断的时候调用一下mappages。
Lazytests and Usertests
这个任务要求我们通过修改上一个任务的代码,从而通过两个非常复杂的程序。这里我遇到了两个非常坑爹的地方。
首先是lazytests里面的oom,我总是在oom之前就发生p->sz整数溢出。发现p->sz是uint64类型的,理论不应该溢出才是。
观察一下原有的sbrk的写法:
1 | int addr; |
这里,大部分人第一次都会去用myproc()->sz=addr+n来修改sbrk,然而这个位置会导致整形溢出,也就是他默认的数据类型会溢出,非常坑爹!
还有一个地方,更加恶心。就是usertests的sbrkargs,我跑了所有其他case都能通过,就这个case无法通过。
经过细致的排查,发现sbrkarg的特殊之处在于,他是在copyin这个函数里面软查找页表的时候产生缺页的,不会产生缺页中断,但是会导致写入失败。所以要在walkaddr里面也处理一下lazy alloc的情况。
也就是说,不是所有缺页都是通过缺页中断驱动的,真是令人作呕的设计啊...
Lab-6 Copy-on-Write Fork for xv6
下面是页表的最后一个实验,实现xv6 fork的COW机制。
超级恶心,写了我整整一天,各种坑点非常多,而且难以debug。这里建议先从给页表进行引用计数下手,一个显而易见的思路是,将kmem改成如下这样:
1 | struct { |
可能有人会疑惑这个引用数组到底开到了RAM的什么地方?其实这个数组会在link的时候开到RAM上,并通过linker算出extern char end[]的位置,所以只要不是太大,并不会影响到整个程序的运行。这个其实就相当于一个无碰撞的hash表,如果想节省内存,还可以搞点复杂的hash表动态扩容啥的,然而嫌麻烦,就没有搞。然后这个freelist记录的就是所有引用计数为0的page了。
后面就需要注意uvmcopy以及缺页中断的情况了。在实验的提示中,他说可以利用RISC-V的RSW位,然而我并没有用这个东西,最后也成功通过了所有的case,核心函数如下:
1 | int |
我最开始的时候把前两个if写反了,导致countfree怎么都通过不了,非常坚硬,研究了半天。要小心谨慎的维护page,基本所有错误都是page的alloc和free导致的。
Lab-7 Multithreading
教材这一部分有点难读,大量内容都在解释有关xv6内部内核线程同步的代码,有些烧脑。幸好作业部分非常简单,完成的非常顺利。
Uthread: switching between threads
这个任务是给xv6添加用户线程,其实跟内核线程的添加方式几乎完全相同,因为没有让我们实现锁机制,所以整体的思路非常简单。
最核心的地方就是切换thread运行的context,这个地方采用跟内核线程一样的方式,只要保存返回地址、栈指针、callee-saved就可以了。
通过阅读xv6教材,我的理解是,其实内核没有进程的概念,只有用户有进程的概念。只是用户进程trap进入内核态之后,有个内核线程与该进程绑定而已。
Using threads
这个任务也非常简单,给一个最简单的开散列hash表加锁,并稍微优化一下性能。
最简单的思路就是每个bucket都加个锁,恰好能达到要求的1.25x的加速:
1 | static |
Barrier
barrier指的就是所有线程都执行到此步之后,在进行后续的程序执行。实际上是对xv6的sleep和wakeup机制的复习。
整体思路也比较简单,只要加锁就好了:
1 | static void |
Lab-8 Locks
教材中主要讲解了xv6系统中各种锁的设计理念。在xv6中,内部锁是由_sync_语句来保证原子性的,感觉这种思路确实相对比较简单。
因为CPU会进行乱序发射之类的指令顺序的优化,所以在很多情况下,需要显式的加上__sync_synchronize(),防止CPU进行跨越该语句的乱序发射。
两个任务具有一定的相似性,一个是优化buffer cache的锁,一个是优化kalloc的锁。我采用的方案也比较相似,在kalloc中,每个CPU弄一个独立的链表,在buffer cache中,每个blockbnum的hash值弄一个独立的链表。
在刚刚开始进行kalloc实验的时候,我走进了一个误区,以为freerange是在每个CPU上面执行的,这里保留一下学习群里的聊天记录,感谢群里的老哥们:
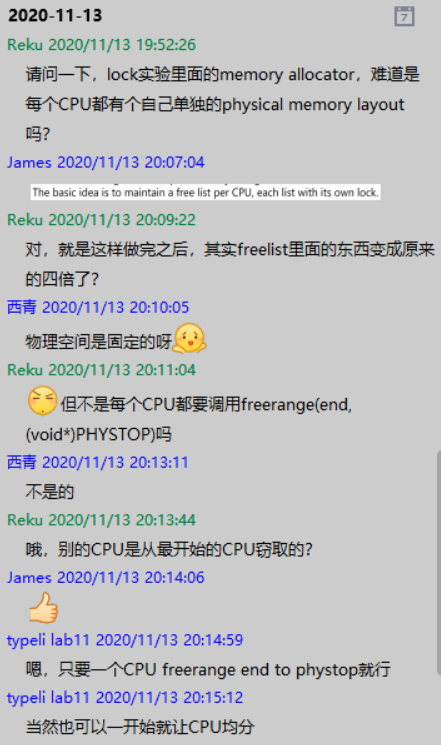
Lab-9 File System
感觉教材阅读起来比较困难,因为整个 File System 是分成 7 层层层抽象来构建的,我边参考代码边读了差不多三四遍,才完全把整个结构理解。整个层级图如下图所示:

Large files
这个任务的难度不是太大,正常的文件 innode 结构是这样的:
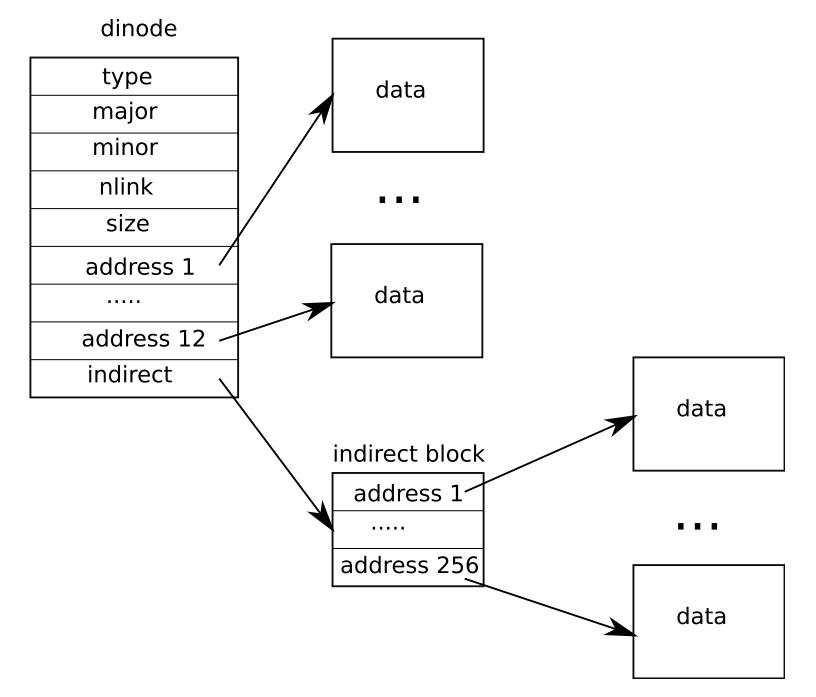
这样的二级结构使得每个文件只能支持 12+256 个 block,可以变成三级结构,使得整个文件能达到 11+256+256*256 个 block。只要小心的修改 itrunc 和 bmap 函数就可以了。
Symbolic links
这个任务的难点在于要清晰的了解他想让你实现的 Symbolic links 行为到底是什么样子的。当 open 不带有 O_NOFOLLOW 标记时,需要一直向下找到 hard link 的位置。整个 symbolic link 的内容都要放在对应的 inode 上面,实际上只需要自己去将文件路径和路径长度保存在 inode 里面就可以了。
open 的修改部分: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21if((omode & O_NOFOLLOW) == 0){
char s[MAXPATH];
int cnt = 0, length;
while(cnt < 10 && ip->type == T_SYMLINK){
cnt ++;
readi(ip, 0, (uint64)&length, 0, 4);
readi(ip, 0, (uint64)s, 4, length);
s[length] = 0;
iunlockput(ip);
if((ip = namei(s)) == 0){
end_op();
return -1;
}
ilock(ip);
}
if(cnt >= 10 && ip->type == T_SYMLINK){
iunlockput(ip);
end_op();
return -1;
}
}
sym_link: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31int
len(char *s)
{
int cnt;
for(cnt = 0; cnt < MAXPATH; cnt ++){
if(s[cnt] == 0) break;
}
return cnt;
}
uint64
sys_symlink(void)
{
char target[MAXPATH], path[MAXPATH];
struct inode *ip;
if(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)
return -1;
begin_op();
if((ip = create(path, T_SYMLINK, 0, 0)) == 0){
end_op();
return -1;
}
int length = len(target);
writei(ip, 0, (uint64)&length, 0, 4);
writei(ip, 0, (uint64)target, 4, length + 1);
iunlockput(ip);
end_op();
return 0;
}
Lab-10 Mmap
这个实验的难点在于,mmap 要实现成 lazy alloc 的形式,所以要对页表进行大量的操作,然而做到 lab-10 可能前面页表的细节已经完全忘干净了(
不过缺点也在于测试样例过于简单,感觉覆盖的场景非常不完全。
对于这个 lazy alloc 的处理,我选择了一种比较取巧的方式,就是在开始的时候完全按照 lazy alloc 的那个方式来写,在最后判断的时候,多加一个 mmap 的判断:
1 | void |
另一个比较麻烦的地方就是对 munmap 的处理,因为题目保证了 munmap 要么截断前面,要么截断后面,不会截断中间,所以要对这几种情况进行调整:
1 | uint64 |
需要注意的是,我们在 writei 的时候,截断的 offset 要补入 p->mmaps[i] 的 offset 中,这样才能找到正确的 offset。
Lab-11 Networking
最后一个实验了,非常简单,就是让我们实现 e1000_transmit 和 e1000_recv 这两个函数。看起来仿佛非常复杂,实际上按照 hint 模拟就好了。
但是有个地方需要注意,在 hint 中, e1000_recv 实现方式如下:
Some hints for implementing e1000_recv: First ask the E1000 for the ring index at which the next waiting received packet (if any) is located, by fetching the E1000_RDT control register and adding one modulo RX_RING_SIZE. Then check if a new packet is available by checking for the E1000_RXD_STAT_DD bit in the status portion of the descriptor. If not, stop. Otherwise, update the mbuf's m->len to the length reported in the descriptor. Deliver the mbuf to the network stack using net_rx(). Then allocate a new mbuf using mbufalloc() to replace the one just given to net_rx(). Program its data pointer (m->head) into the descriptor. Clear the descriptor's status bits to zero. Finally, update the E1000_RDT register to be the index of the last ring descriptor processed. e1000_init() initializes the RX ring with mbufs, and you'll want to look at how it does that and perhaps borrow code. At some point the total number of packets that have ever arrived will exceed the ring size (16); make sure your code can handle that.
但是在实际实现中,net_rx要先release锁之后才能去运行,不然就会panic:
1 | static void |